自然語言處理(上)
Chap01 Introduction
Applications of NLP
- Machine translation
- google translate
- Speech recognition
- Siri
- Smart input method
- ㄐㄅㄈㄏ → 加倍奉還
- Sentiment(情感) analysis
- Information retrieval
- Question Anwering
- Turing Test
- Optical character recognition (OCR)
Critical Problems in NLP
- Ambiguity(不明確性)
- The most important thing in NLP
- Lexical(字辭)
current: noun or adjectivebank(noun): money or river
- Syntactic(語法)
[saw [the boy] [in the park]][saw [the boy in the park]]
- Semantic(語義)
- "John kissed his wife, and so did Sam". (Sam kissed John's wife or his own?)
- agent(施事) vs. patient(受事)
- ill-form(bad form)
- typo
- grammatical errors
- Robustness
- various domain
- 網路語言:取材於方言俗語、各門外語、縮略語、諧音、甚至以符號合併以達至象形效果等等
- emoticon(表情符號)
Main Topics in Large-Scale NLP Design
- Knowledge representation
- organize and describe linguistic knowledge
- Knowledge strategies
- use knowledge for efficient parsing, ambiguity resolution, ill-formed recovery
- Knowledge acquisition
- setup and maintain knowledge base systematically and cost-effectively
- Knowledge integration
- consider various knowledge sources effectively
Models
用演算法來轉換文字結構,以產生最後結果
- State machines
- Rule-based approaches
- Logical formalisms
- Probabilistic models
Approaches
NLP start from 1960, statictics method wins after 1995
Rule-based approach
- Advantages
- No need database
- Easy to incorporate with knowledge
- Better generalization to a unseen domain
- Explainable and traceable
- easy to understand
- Disadvantages
- Hard to maintain consistency (at different situation)
- Hard to handle uncertain knowledge (define uncertainty factor)
- irregular information
- Not easy to avoid redundancy
- Knowledge acquisition is time consuming
Corpus(語料庫)-based approach
- Advantages
- Knowledge acquisition can be automatically achieved by the computer
- Uncertain knowledge can be objectively quantified(知識可被量化)
- Consistency and completeness are easy to obtain
- Well established statistical theories and technique are available
- Disadvantages
- Generalization is poor for small-size database
- Unable to reasoning
- Hard to identify the effect of each parameter
- Build database is time consuming
- Corpus
- Brown Corpus (1M words),Birmingham Corpus (7.5M words), LOB Corpus (1M words), etc
- Corpora(語料庫(複數)) of special domains or style
- Newspaper, Bible, etc
- Information in Corpora
- pure-text corpus
- language usage of real world, word distribution, co-occurrence
- tagged corpus
- parts of speech, structures, features
- pure-text corpus
Hybrid approach
- Use rule-based approach when
- there are rules that have good coverage
- it can be governed by a small number of rules
- extensional knowledge is important to the system
- there are rules that have good coverage
- Use corpus-based approach when
- Knowledge needed to solve the problem is huge and intricate
- A good model or formulation exists
Implementation
Natural Language Toolkit(NLTK): Open source Python modules, linguistic data and documentation for research and development in natural language processing
features
- Corpus readers
- Tokenizers
- whitespace, newline, blankline, word, treebank, sexpr, regexp, Punkt sentence segmenter
- Stemmers
- Porter, Lancaster, regexp
- Taggers
- regexp, n-gram, backoff, Brill, HMM, TnT
- Chunkers
- regexp, n-gram, named-entity
- Metrics
- accuracy, precision, recall, windowdiff, distance metrics, inter-annotator agreement coefficients, word association measures, rank correlation
- Estimation
- uniform, maximum likelihood, Lidstone, Laplace, expected likelihood, heldout, cross-validation, Good-Turing, Witten-Bell
- Miscellaneous
- unification, chatbots, many utilities
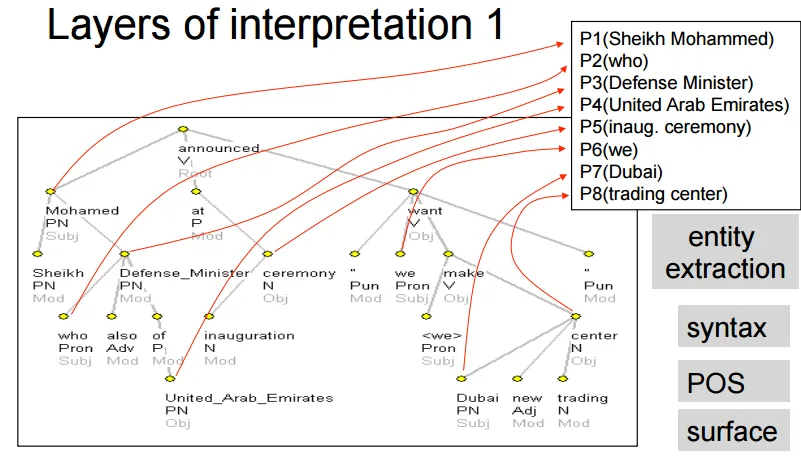
Chap02 Overall Pictures
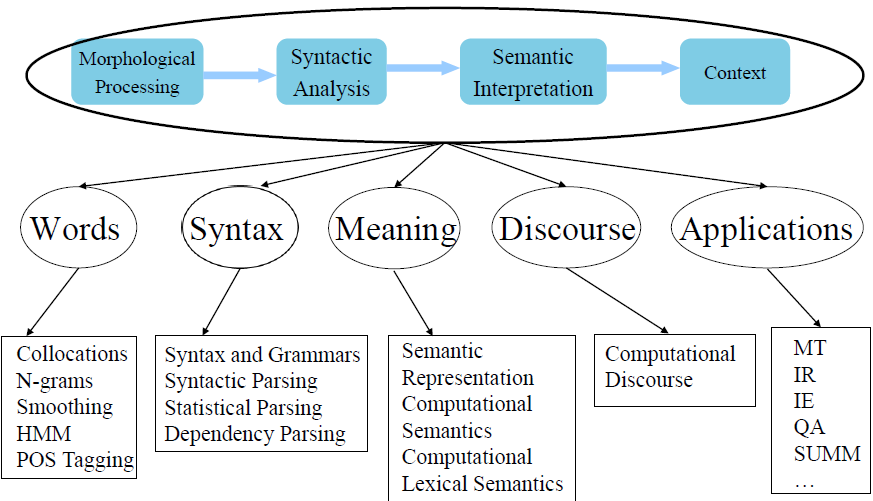
Knowledge Categories
- Phonology(聲音,資料來源)
- Morphology(詞性)
- Syntax(句構)
- Semantics(語義)
- Pragmatics(句子關聯,語用學)
- Discourse(篇章分析,話語)
Morphology(Structure of words)
- part-of-speech(POS) tagging(詞性標註, lexical category)
- find the roots of words
- e.g., going → go, cats → cat
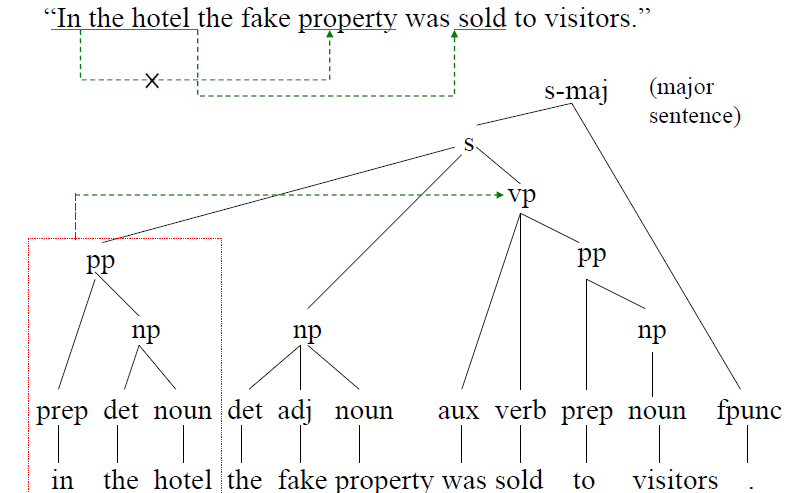
Syntax(structure of sentences)
- Context-Free Grammars(CFG)
![parse tree]()
- Chomsky Normal Form(CNF)
- can only use following two rules
non-terminal → terminalnon-terminal → non-terminal non-terminal
- can only use following two rules
- dependency
- local dependency
- words near together would probably have the same syntax rule
- long-distance dependency
- wh-movement(疑問詞移位)
- What did Jennifer buy? → 什麼 (助動詞) 珍妮佛 買了
- 分裂句 Right-node raising
- [[she would have bought] and [he might sell]] shares
- Argument-cluster coordination
- I give [[you an apple] and [him a pear]]
- challenge for some statistical NLP approaches (like n-grams)
- wh-movement(疑問詞移位)
- local dependency
Semantics(meaning of individual sentences)
- semantic roles
- agent(主詞)
- patient(受詞)
- instrument(工具)
- goal(目標)
- Beneficiary(受益)
- He threw the book(patient) at me(goal)
- John sold the car for a friend(beneficiary)
- Subcategorizations(次分類)
- 及物、不及物動詞
- Semantics can be divided into two parts
- Lexical Semantics
- 上下位,同義(反義),部分-整體
- Composition Semantics
- 合起來的意義與單一字意義不同
- Lexical Semantics
- Implementation
- WordNet®(large lexical database of English)
- Thesaurus(索引典)
- 同義詞詞林
- 廣義知網中文詞知識庫(E-HowNet)
- FrameNet
FrameNet
A dictionary of more than 10,000 word senses, 170,000 manually annotated sentences
Frame Semantics(Charles J. Fillmore)
- the meanings of most words can be more understood by semantic frame
- Including description of a type of event, relation, or entity and the participants in it
- Example:
apply_heatframe- When one of these words appear, this frame will be applied
Fry(炸),bake(烘),boil(煮), a`nd broil(烤)
- Frame elements: Cook, Food, Heating_instrument and Container
- a person doing the cooking (Cook)
- the food that is to be cooked (Food)
- something to hold the food while cooking (Container)
- a source of heat (Heating_instrument)
- [
Cookthe boys] ... GRILL [Foodfish] [Heating_instrumenton an open fire]
- When one of these words appear, this frame will be applied
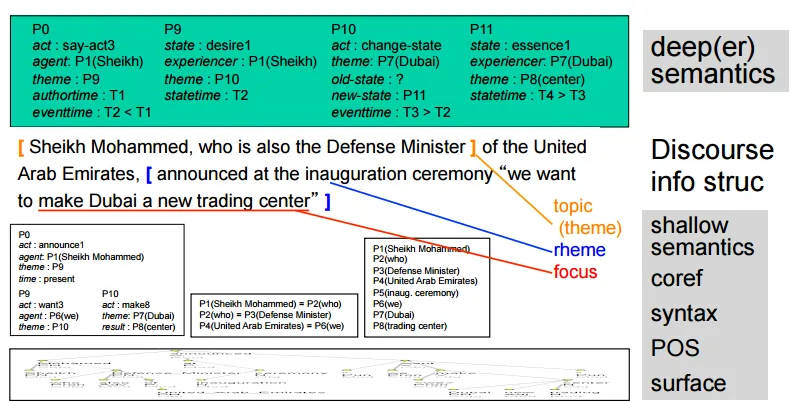
Pragmatics(how sentences relate to each other)
- explain what the speaker really expressed
- Understand the scope of
- quantifiers
- speech acts
- discourse analysis
- anaphoric relations(首語重複)
- Anaphora(首語重複) and Coreference(指代)
- 張三是老師,他教學很認真,同時,他也是一個好爸爸。
- Type/Instance: “老師”/“張三”, “一個好爸爸”/“張三”
- crucial to information extraction
- Dialogue Tagging
![]()
Discourse Analysis
Example
- 1a: 佛羅倫斯哪個博物館在1993年的爆炸事件中受到破壞?
- 1b: 這個事件哪一天發生?
- 問句1b「這個事件」,指的是問句1a「1993年的爆炸事件」
Summary
From The Three (and a Half) Futures of NLP
- NLP is Notation Transformation(e.g. English → Chinese), with some information(POS, syntatic, senmatic...) added
- Much NLP is engineering
- select and tuning learning performance
- Knowledge is crucial in language-related research areas, but providing a large scaleknowledge base is difficult and costly
- Knowledge Base
- WordNet
- FrameNet
- Wikipedia
- Dbpedia
- Freebase
- Siri
- Google Knowledge Graph
- Knowledge Base
- Hierarchy of transformations(由深至淺)
- pragmatics, writing style
- deeper semantics, discourse
- shallow semantics, co-reference
- syntax, POS(part-of-speech)
- shallow semantics, co-reference
- deeper semantics, discourse
- 分析時由淺至深
- pragmatics, writing style
Analysis
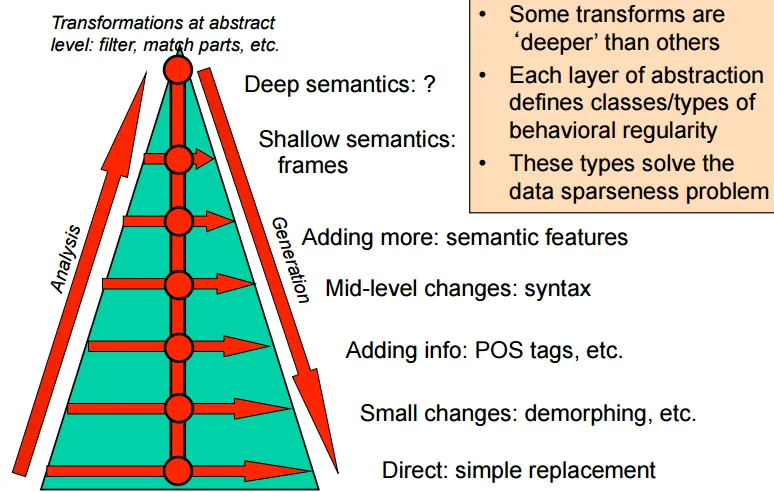

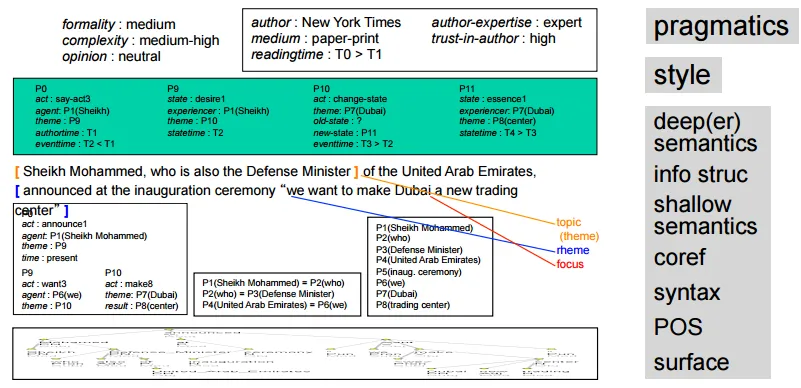
NLP progress by now



Chap03 Collocations(搭配詞)
- 多個單字組合成一個有意義的語詞,其意義無法從各個單字中推得
- e.g. black market
- Subclasses of Collocations
- compound nouns
- telephone box and post office
- idioms
- kick the bucket(氣絕)
- Light verbs(輕動詞)
- 動詞失去其意義,需要和其他有實質意義的詞作搭配
- e.g. The man took a walk(walk, not take) vs The man took a radio(take)
- Verb particle constructions(語助詞) or Phrasal Verbs(詞組動詞, 短語動詞, V + 介系詞)
- take in = deceive, look sth. up
- proper names
- San Francisco
- Terminology(專有名詞)
- compound nouns
- Classification
- Fixed expressions
- in short (O)
- in shorter or in very short(X)
- Semi-fixed expressions(可用變化形)
- non-decomposable idioms
- kick the bucket (O)
- he kicks the bucket(O)
- the bucket was kicked (X)
- compound nominals
- car park, car parks
- Proper names
- non-decomposable idioms
- Syntactically-Flexible Expressions
- decomposable idioms
- let the cat out of the bag
- verb-particle constructions
- light verbs
- decomposable idioms
- Institutionalized Phrases (習慣用法)
- salt and pepper(○) pepper and salt(×)
- traffic light
- kindle excitement(點燃激情)
- Fixed expressions
Collocation detection
- by Frequency
- by Mean and Variance of the distance between focal word (焦點詞) and collocating word(搭配詞)
- Hypothesis Testing
- Mutual Information
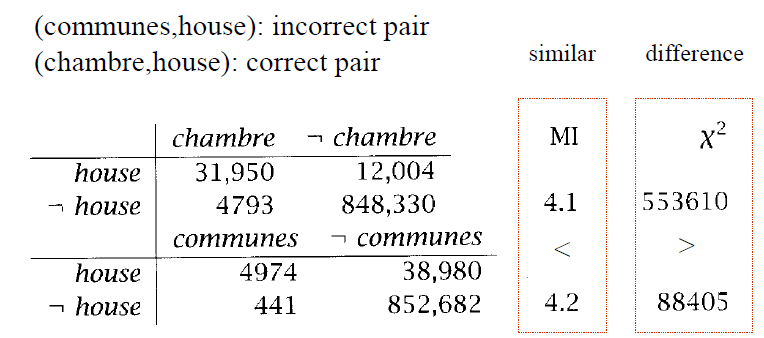
By Frequency
- 找出現機率大的bigrams
- not always significant
- 篩選可能為組合詞的詞性組合(Ex. adj+N)
- The collocations found
![]()
- What if a word have two possible collocations?(strong force, powerful force)
![]()
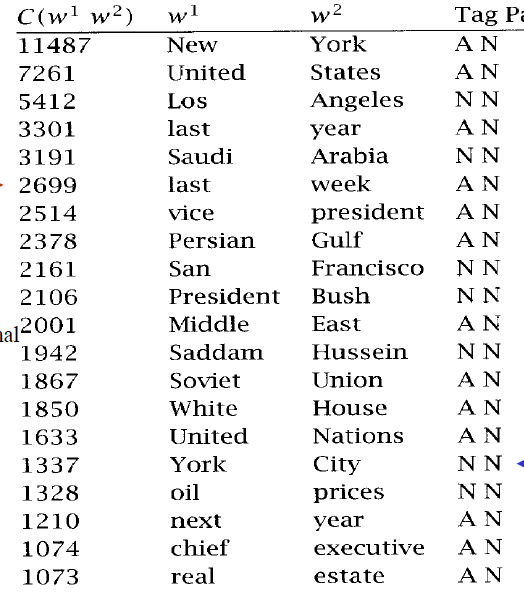
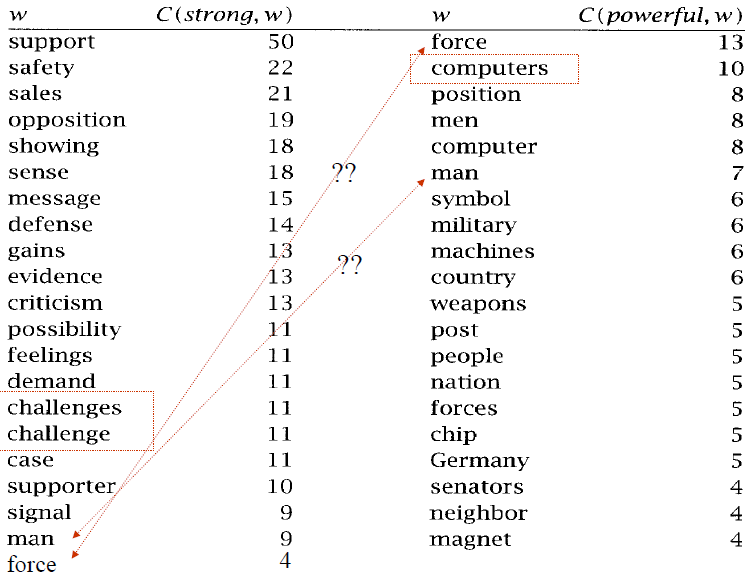
By Mean and Variance of the distance between focal word(焦點詞) and collocating word(搭配詞)
- many collocations consist of more flexible relationships
- frequency is not suitable
- Define a collocational window
- e.g., 3-4 words before/after
- assemble every word pair as a bigram
- e.g., A B C D → AB, AC, AD, BC, BD, CD
- computes the mean and variance of the offset between the two words
- 變異數愈低,代表兩個字之間的位置關聯愈固定
![]()
- 變異數愈低,代表兩個字之間的位置關聯愈固定
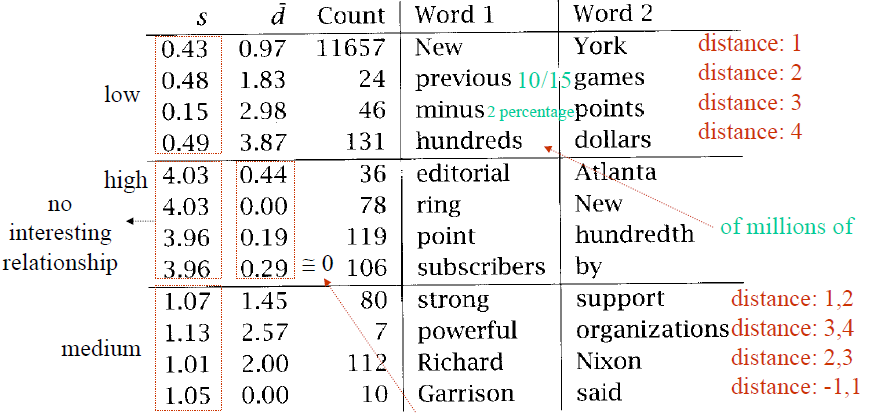
- z-score $z = {freq - \mu \over \sigma}$: the strength of a word pair
Hypothesis Testing(假設檢定)
- Even high frequency and low variance can be accidental
- null hypothesis(虛無假設, H0)
- 設 w1 and w2 is completely independent → w1 and w2 不是搭配詞
- P(w1w2) = P(w1)P(w2)
- 設 w1 and w2 is completely independent → w1 and w2 不是搭配詞
- 假設H0為真,計算這兩個字符合H0的機率P
- 若P太低則否決H0(→ 是搭配詞)
- Two issues
- Look for particular patterns in the data
- How much data we have seen
- 種類包括:t檢驗,Z檢驗,卡方檢驗,F檢驗
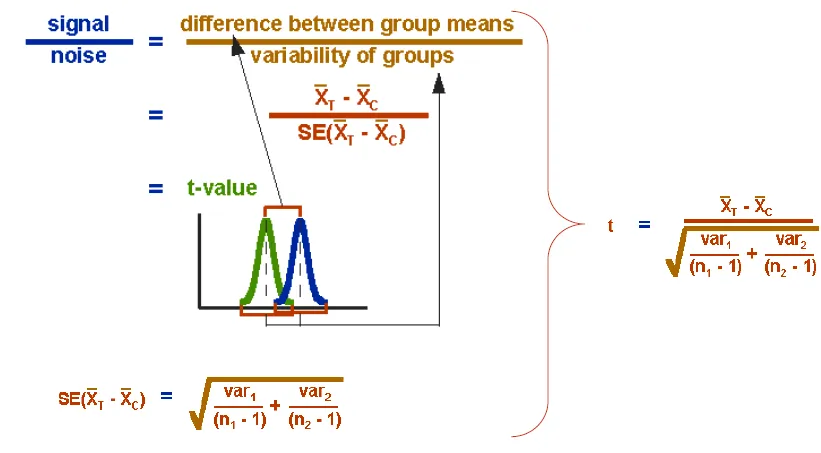
t-test
- Test whether distributions of two groups are statistically different or not
- H0 → (w1, w2) has no differnece with normal distribution
- considering variance of the data
![]()
- formula
![]()
![]()
- Calculate t by alpha level and degree of freedom
- alpha level
α: confidence- in normal distribution,α = 95%落在mean±1.96std之間, α = 99%落在mean±2.576std之間
- If t-value is larger than 2.576, we say the two groups are different with 99% confidence
- degree of freedom: number of sample-1
- total = number of two groups-2
- alpha level
- t↑ → more difference → more possible to reject null hypothesis → more possible to be collocation
- Example: "new" occurs 15,828 times, "companies" 4,675 times, "new companies" 8 times, total 14,307,668 tokens
- Null hypothesis: the occurrences of new and companies are independent(not collocation)
- H0 mean = P(new, companies) = P(new) x P(companies) = $\frac{15828 \times 4678}{14307668^2} = 3.615 \times 10^{-7}$
- H0 var = p(1-p) ~= p when p is small
- tvalue = $\frac{5.591 \times 10^7 - 3.615\times 10^7}{\sqrt{\frac{5.591 \times 10^7}{14307668}}} = 0.999932$
- 0.999932 < 2.576, we cannot reject the null hypothesis
- new company are not collocation
- the above words are possible collocations
![]()


Hypothesis testing of differences
- useful for lexicography
- which word(strong, powerful) is suitable to modify "computer"?
- T-test can be used for comparison of the means of two normal populations
- H0 is that the average difference is 0 (u = 0)
- v1 and v2 are the words we are comparing (e.g., powerful and strong), and w is the collocate of interest(e.g., computers)
![]()
![]()
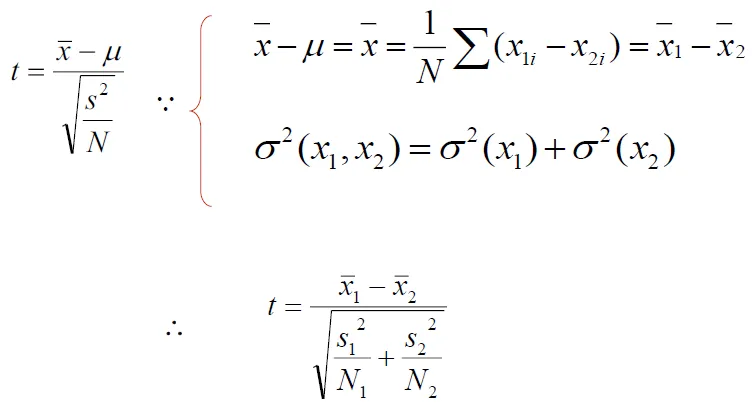
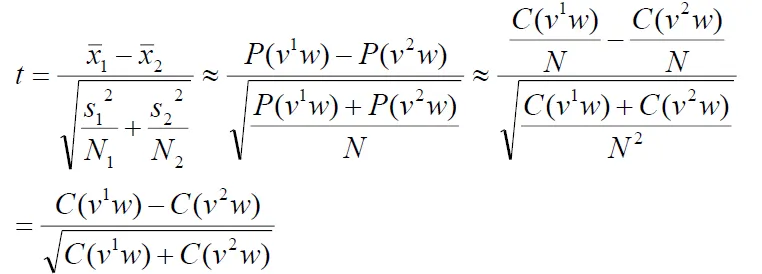
Chi-Square test
- T-test assumes that probabilities are normally distributed
- not really
- Chi-Square: compare observed frequencies with expected frequencies
- If difference between observed and expected frequencies is large, we can reject H0
- Example
- expected frequency of "new companies": $\frac{8+4667}{14307668} \times \frac{8+15820}{14307668} \times 14307668$ = 5.2
![]()
- chi-square value = χ^2
![]()
![]()
- When α=0.05, χ^2=3.841
- Because 1.55<3.841, we cannot reject the null hypothesis. new companies is not a good candidate for a collocation
- expected frequency of "new companies": $\frac{8+4667}{14307668} \times \frac{8+15820}{14307668} \times 14307668$ = 5.2
- Comparison with T-test
- The 20 bigrams with the highest t scores in the test corpus are also the 20 bigrams with the highest χ^2 scores
- χ^2 is appropriate for large probabilities(t-test is not because of normality assumption)
- Application: Translation
- find similarity of word pairs

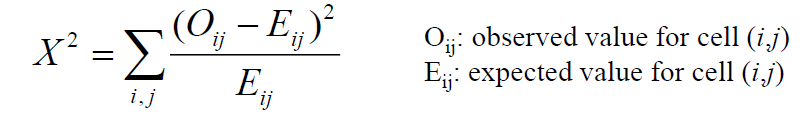
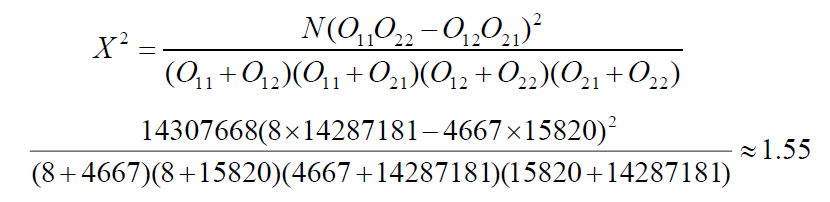
Likelihood Ratios
- Advantage compared with Chi-Square test
- more appropriate for sparse data
- easier to interpret
Likelihood Ratios within single corpus
- examine two hypothesis
- H1: occurrence of w2 is independent of the previous occurrence of w1(null hypothesis)
- H2: occurrence of w2 is dependent of the previous occurrence of w1
- maximum likelihood estimate
![]()
- using binomial distribution
- $b(k;n, x) = \binom nk x^k \times (1-x)^{n-k}$
- only different at probability
- $L(H_1) = b(c_{12};c_1, p)b(c_2-c_{12}; N-c_1, p)$
- $L(H_2) = b(c_{12};c_1, p_1)b(c_2-c_{12}; N-c_1, p_2)$
![likely probability]()
- log of likelihood ratio λ
![log likelihood ratio]()
- use D = -2logλ to examine the significance of two words, which can asymptotically(漸近) chi-square distributed

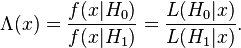
Likelihood Ratios between two or more corpora
- useful for the discovery of subject-specific collocations
Mutual Information
- measure of how much one word tells us about the other(information theory)
- pointwise mutual information(PMI)
![PMI formula]()
- MI是在獲得一個隨機變數的資訊之後,觀察另一個隨機變數所獲得的「資訊量」(單位通常為位元)
- mutual information = Expection(PMI)
![]()
- works bad in sparse environments
- As the perfectly dependent bigrams get rarer, their mutual information increases → bad measure of dependence
![]()
- As the perfectly dependent bigrams get rarer, their mutual information increases → bad measure of dependence
- good measure of independence
- when perfect independence, I(x, y) = 0
![]()
- New formula: $C(w1w2)I(w1w2)$
- With MI, bigrams composed of low-frequency words will receive a higher score than bigrams composed of high-frequency words
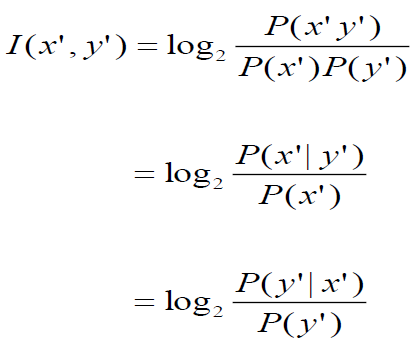

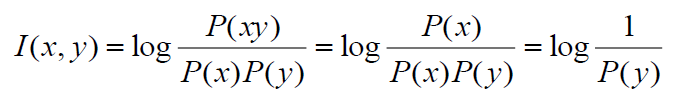
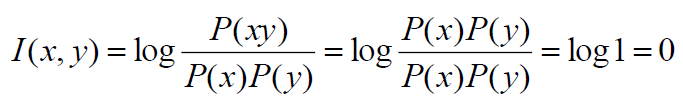
Chain rule for entropy
- $H(X,Y) = H(Y|X) + H(X) = H(X|Y) + H(Y)$
- Conditional entropy $H(Y|X)$ expresses how much extra information you still need to supply on average to communicate Y when X is known
![]()
- $H(X)-H(X|Y) = H(Y)-H(Y|X)$
- This difference is called the mutual information between X and Y(X, Y共同擁有的information)
- MI is not similar to chi-square
![]()
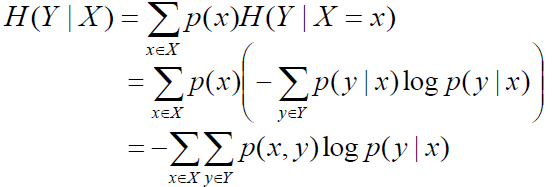
Entropy
- Entropy: uncertainty of a variable
![]()
- Incorrect model’s cross entropy is larger than correct model's
![]()
- 正確model和猜測model的差別:P(X)logP(X) ↔ P(X)logPM(X)
- Entropy Rate: Per-word entropy(= sentence entropy / N)
![]()
- Cross Entropy: average informaton needed to identify an event drawn from the set between two probability distributions
- 交叉熵的意義是用該模型對文本識別的難度,或者從壓縮的角度來看,每個詞平均要用幾個位來編碼
![]()
- Joint entropy H(X, Y): average information needed to specify both values
![]()
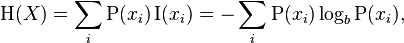
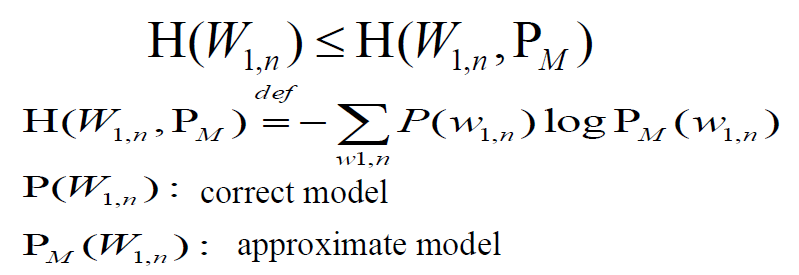


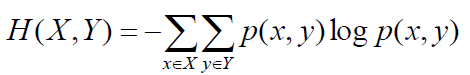
Case Study
Emotion Analysis
- Non-verbal Emotional Expressions
- text (raw) and emoticons(表情符號) (tag) form collection
- appearance of an emoticon is a good emotion indicator to sentences
- check the dependency of each word in sentences
- Evaluation
- Use top 200 lexiconentries as features
- Tag={Positive, Negative}
- LIBSVM
Chap04 N-gram Model
N-grams are token sequences of length N
applications
- Automatic speech recognition
- Author Identification
- Spelling correction
- Grammatical Error Diagnosis
- Machine translation
Counting
- Example: I do uh main-mainly business data processing
- Should we count “uh”(pause) as tokens?
- What about the repetition of “mainly”? Should such do-overs count twice or just once?(重複)
- The answers depend on the application
- "uh" is not needed for query
- "uh" is very useful in dialog management
- Corpora: Google Web Crawl
- 1,024,908,267,229 English tokens
- 13,588,391 wordform types
- even large dictionaries of English have only around 500k types. Why so many here?
- Numbers
- Misspellings
- Names
- Acronyms(縮寫)
Language model
Language models assign a probability to a word sequence
Ex. P(the mythical unicorn) = P(the) * P(mythical | the) * P(unicorn | the mythical)
- Markov assumption: the probability of a word depends only on limited previous words
- Generalization: n previous words, like bigram, trigrams, 4-grams......
- As we increase the value of N, the accuracy of model increases
N-Gram probabilities come from a training corpus
overly narrow corpus: probabilities don't generalize
overly general corpus: probabilities don't reflect task or domain
maximum likelihood estimate
- maximizes the probability of the training set T given the model M
- Suppose the word “Chinese” occurs 400 times in a corpus
- MLE estimate is 400/1000000 = .004
- makes it most likely that “Chinese” will occur 400 times in a million word corpus
- P([s] I want englishfood [s]) = P(I|[s]) x P(want|I) x P(english|want) x P(food|english) x P([s]|food) = 0.000031$
Usage
-
capture some knowledge about language
- World Knowledge
- P(english food|want) = .0011
- P(chinese food|want) = .0065
- syntax
- P(to|want) = .66
- P(eat| to) = .28
- P(food| to) = 0
- discourse
P(i|<s>)= .25
- World Knowledge
-
Shannon’s Method: use language model to generate random sentences
- Shakespeare as a Corpus
- 99.96% of the possible bigrams were never seen (have zero entries in the table)
- This is the biggest problem in language modeling
- Shakespeare as a Corpus
Evaluating N-Gram Models
- Extrinsic(外在的) evaluation
- Compare performance of the application within two models
- time-consuming
- Intrinsic evaluation
- perplexity
- But get poor approximation unless the test data looks just like the training data
- not sufficient to publish
- perplexity
Standard Method
- Train → Test
- A dataset which is different from our training set, but both drawn from the same source
- use evaluation metric(Ex. perplexity)
- Example
- Create a fixed lexicon L, of size V
- At text normalization phase, any training word not in L changed to UNK(unknown word token)
- count UNK like a normal word
- When testing, also use UNK counts for any word not in training
- The best language model is one that best predicts an unseen test set
- Create a fixed lexicon L, of size V
perplexity(複雜度)
- Definition
- notion of surprise
- The more surprised the model is, the lower probability it assigned to the test set
- Minimizing perplexity is the same as maximizing probability
- notion of surprise
- probability of a test set, as normalized by the number of words
![]()
- 物理意義是單詞的編碼大小
- 如果在某個測試語句上,語言模型的perplexity值為2^190,說明該句子的編碼需要190bits
- relate to entropy
- Perplexity(p, q) = $2^{H(p,q)}$
- p is the test sample distribution, and q is the distribution of language model
- do everything in log space to avoid underflow and calculate faster
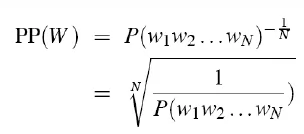
word entropy
- word entropy for English
- 11.82 bits per word [Shannon, 1951]
- 9.8 bits per word [Grignetti, 1964]
- word entropy in medical language
- 11.15 bits per word
Chap05 Statistical Inference
- Statistical Inference:taking some data (generated by unknown distribution) and then making some inferences(推理,推測) about this distribution
- three issues
- Dividing the training data into equivalence classes
- Finding a good statistical estimator for each equivalence class
- Combining multiple estimators
Form Equivalence Class
- Classification Problem
- predict target feature based on various classificatory features
- reliability v.s. discrimination
- The more classes, the more discrimination, but estimation feature is not reliable
- Independent assumption
- assume data is nearly independent
- Statistical Language Modeling
![]()
- Language Model: P(W)
- LM does not depend on acoustics
- the acoutstics probability is constant(calculated by data)
- n-gram model
- assume equivalence classes are previous n-1 words
- Markov Assumption: Only the prior n-1 local context affects the next entry
- (n-1)th Markov Model or n-gram
- Building n-grams
- Remove punctuation(標點) and normalize text
- Map out-of-vocabulary words to unknown symbol(UNK)
- Estimate conditional probabilities by joint probabilities
- P(n | n-2, n-1) = P(n-2, n-1, n) / P(n-2, n-1)
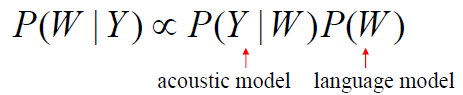
Finding statistical estimator
- Goal: derive probability estimate of target feature based on observed data
- Running Example
- From n-gram data P(w1,..,wn), predict P(wn|w1,..,wn-1)
- Solutions
- Maximum Likelihood Estimation
- Laplace’s, Lidstone’s and Jeffreys-Perks’ Laws
- Held Out Estimation
- Cross-Validation
- Good-Turing Estimation
- Model combination
- Combine models (unigram, bigram, trigram, …) to use the most precise model available
- interpolation(內插) and back-off(後退)
- use higher order models when model has enough data
- back off to lower order models when there isn’t enough data
Terminology
- Ex.
[s] a b a b a- N = 5 (
[s]a,ab,ba,ab,ba) - B = 3 (
[s]a,ab,ba) - C(w1, w2...) = 某N-gram(Ex. ab)出現次數
- r = 某N-gram出現頻率
- Nr = 有幾個「出現r次的N-gram」
- Tr = 出現r次的N-gram,在test data出現的總次數
- N = 5 (
(1) Maximum Likelihood Estimation
- usually unsuitable for NLP
- sparseness of the data(a lot of word sequences with zero probabilities)
- Use Discounting or Smoothing technique to improve
- Smoothing
- Smoothing is like Robin Hood: Steal from the rich and give to the poor
- no word sequences has 0 probability
![]()
- Discounting
- assign some probability to unseen events
- Smoothing

(2) Laplace’s, Lidstone’s and Jeffreys-Perks’ Laws
- Laplace: add 1 to every count
- gives far too much probabilities to unseen events
- Usage: In domains where the number of zeros isn’t so huge
- pilot studies
- document classification
- Lidstone and Jeffreys-Perks: add a smaller value λ < 1
- B:number of bins
![lid]()
- Expected Likelihood Estimation (ELE)(Jeffreys-Perks Law)
- λ=1/2
- B:number of bins
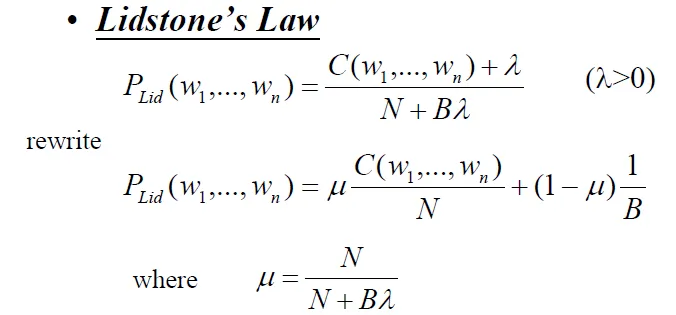
(3) Held Out Estimation
- compute frequencies in training data and held out data
![]()
- Tr / Nr = Average frequency of training frequency r N-grams
- estimate frequency(value for validation)
- 計算出現在training corpus r次的bigrams,在held-out corpus出現的次數稱為Tr。 因為這種bigrams有Nr個,因此平均為Tr / Nr
- Tr / Nr = Average frequency of training frequency r N-grams
- Validation
- if the probabilities estimated on training data are close to those on held-out data, it's a good language model
- 參考資料--validation in machine learning
- Prevent Overtraining(overfit)
- test on different data
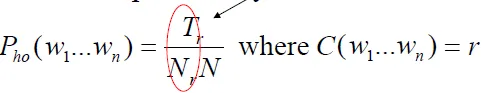
Training portion and testing portion (5-10% of total data)
- Held out data (validation data)
- available training data: real training data(90%) + held out data(10%)
- Instead of presenting a single performance figure, testing result on each smaller sample
- Using t-test to reject the possibility of an accidental difference
(4) Cross-Validation
If data is not enough, use each part of the data both as training data and held out data
- Deleted Estimation
- $N_r^a$ = number of n-grams occurring r times in the a th part of the training data
- $T_r^{ab}$ = number of occurs in part b of 「bigrams occurs r times in part a」
![]()
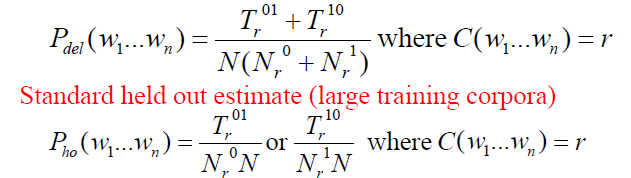
- Split the training data into K sections
- For each section k: hold-out section k and compute counts from remaining K-1 sections; compute Tr(k)
- Estimate probabilities by averaging over all sections
estimate frequency of deleted estimation 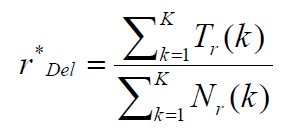
(5) Good-Turing Estimation
- 用出現一次的來預測沒出現過的
- 若出現次數>k,不變,否則套用公式
![]()
- renormalize to sum = 1
- Simple Good-Turing
- replace any zeros in the sequence by linear regression:
log(Nc) = a+blog(c)
- replace any zeros in the sequence by linear regression:
- after good-turing
![]()

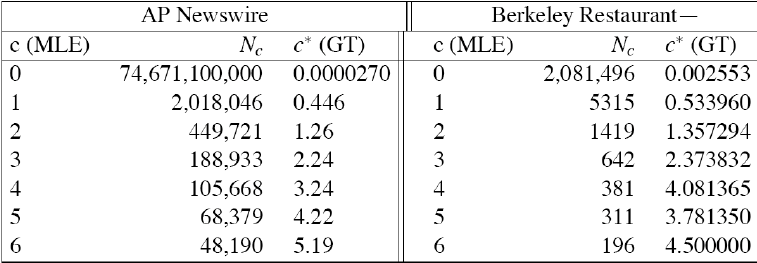
explaination from stanford NLP course
- when use leave-one-out validation, the possibilities of unseen validation data is $\frac{N_1}{N}$(when thing-saw-once is the validation data), the possibilities of validation data have been seen K times is $\frac{(k+1)N_{k+1}}{N}$
- Josh Goodman's intuition: assume You are fishing, and caught 10 carp,3 perch,2 whitefish, 1 trout, 1 salmon, 1 eel = 18 fish
- P(unseen) = N1/N0 = N1/N = 3/18
- C(trout) = $2 \times N_2/N_1$ = $2 \times (1/3)$ = 2/3
- P(trout) = 2/3 / 18 = 1/27
- for large k, often get zero estimate, so do not change the count
- C(the) = 200000, C(a) = 190000, $C*(the) = (200001)N_{200001} / N_{200000} = 0 (because N_{200001} = 0)$
(6) Absolute Discounting
從所有非零N-gram中拿出λ,平均分配給所有未出現過的N-gram
Combining Estimator
Combination Methods
- Simple Linear Interpolation(內插)(finite mixture models)
- Ex. trigram, bigram and unigram
![]()
- More generally, λ can be a function of (wn-2, wn-1, wn)
- use Expectation-Maximization (EM) algorithm to get weights
- Ex. trigram, bigram and unigram
- General Linear Interpolation
- general form for a linear interpolation model
- weights are a function of the history
![]()
- Katz’s Backing-Off
- choose proper order to train model (base on training data)
- If the n-gram appeared more than k times
- use MLE estimate and discount it
- If the n-gram appeared k times or less
- use an estimate from lower-order n-gram
- If the n-gram appeared more than k times
- back-off probability
![]()
- $P_{Dis}(w_n|w_{n-2},w_{n-1})$ is specific discounted estimate. e.g., Good-Turing or Absolute Discounting
- unseen trigram is estimated by bigram and β
![]()
- β(wn-2, wn-1) and α are chosen so that sum of probabilities = 1
- more genereal form
![]()
- choose proper order to train model (base on training data)
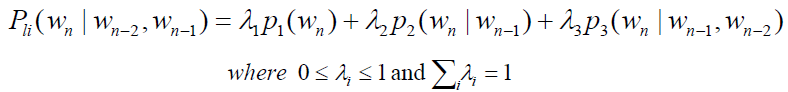
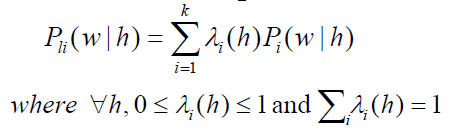
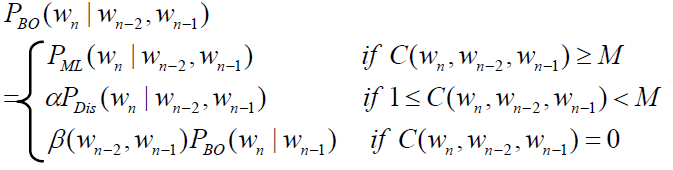
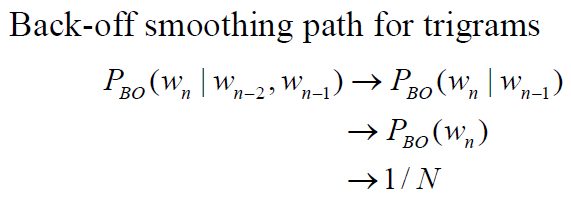
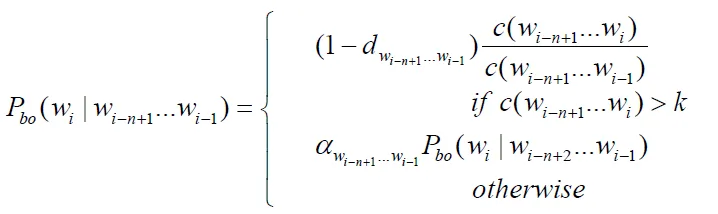
Most usual approach in large speech recognition: trigram language model, Good-Turing discounting, back-off combination
Chap06 Hidden Markov Models(HMM)
- statistical tools that are useful for NLP
- part-of-speech-tagging
- We construct “Visible” Markov Models in training, but treat them as Hidden Markov Models when tagging new corpora
- model a state sequence (perhaps through time) of random variables that have dependencies
- 狀態(state)並不是直接可見的,但受狀態影響的某些變量(output symbol)則是可見的
- known value
- output symbols(words) 字詞
- probabilistic function of state relation 和state相關的機率函式
- unknown value
- state(part-of-speech tags) 目前的state,即POS tag
- rely on 2 assumptions
- Let X=(X1, ..., XT) be a sequence of random variables, X is markov chain if
- Limited Horizon
- a word’s tag only depends on previous tag(state只受前一個state影響)
- Time Invariant
- the dependency does not change over time(轉移矩陣不變)
Description
- initial state π, state = Q, Observations = O, transition matrix = A, output(observation) matrix = B
![]()
- $a_{ij}$ = probability of state $q_i$ transition to state $q_j$
- $b_i(k)$ = probability of observe output symbol $O_k$ when state = $q_i$

3 problems of HMM
中文解說:隱馬可夫鏈
- 評估(Evaluation):what is probability of the observation sequence given a model? (P(Observes|Model))
- Used in model improvement
- Used in classification
- Word spotting in speech recognition, language identification, speaker identification, author identification……
- Given an observation, compute P(O|model) for all models
- Use Forward algorithm to solve it
- 解碼(Decoding):Given an observation sequence and model, what is the most likely state sequence? (P(States|Observes, Model)) 下一個state是什麼
- Used in tagging (tags=hidden states)
- Use Viterbi algorithm to solve it
- 學習(Learning):Given an observation sequence, infer the best model parameters (argmax(Model) P(Model|Observes))
- 「fill in model parameters that make the observation sequence most likely」
- Used for building HMM Model from data
- Use EM(Baum-Welch, backward-forward algorithm) to solve it
Solutions of HMM problem
Forward
![]()
- simply sum of the probability of each possible state sequence
- Direct evaluation
- time complexity = $(2T+1) \times N^{T+1}$ -> too big
![]()
- time complexity = $(2T+1) \times N^{T+1}$ -> too big
- Use dynamic programming
- record the probability of subpaths of the HMM
- The probability of longer subpaths can be calculated from shorter subpaths
- similar to Viterbi: viterbi use MAX() instead of SUM()
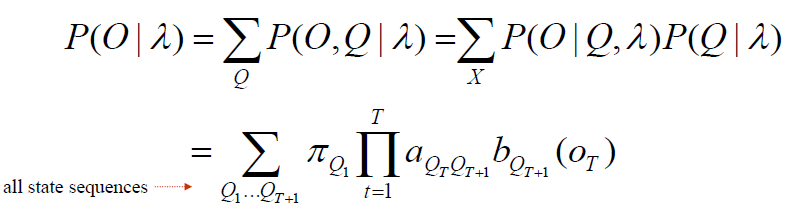
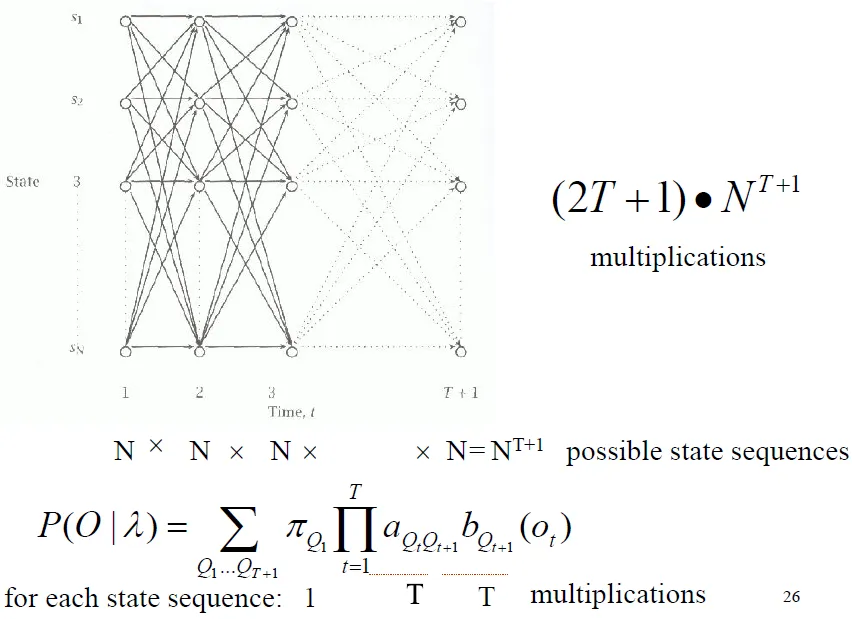
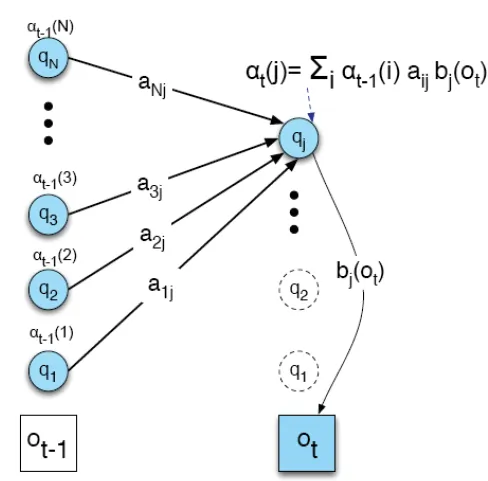
Forward Algorithm
- $α_t(i)$ = probability of state = qi at time = t
![dp]()
- α的求法:將time = t-1 的 α 值,乘上在time = t時會在qi state的機率,並加總
![dp]()
- 順向推出所有可能的state sequence會產生此observation的機率和, 即為此model會產生此observation的機率
![dp]()
- Σ P($O_1, O_2, O_3$ | possible state sequence) = P($O_1, O_2, O_3$ | Model)
![dp]()

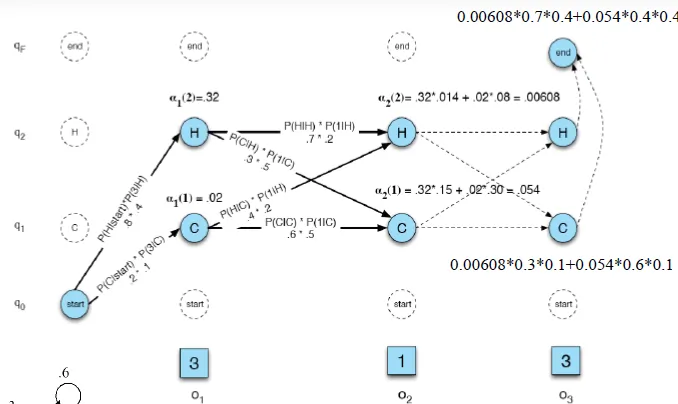

Example:Urn(甕)
- genie has two urns filled with red and blue balls
- genie selects an urn and then draws a ball from it
- The urns are hidden
- The balls are observed
- After a lot of draws
- know the distribution of colors of balls in each urn(B matrix)
- know the genie’s preferences in draw from one urn or the next(A matrix)
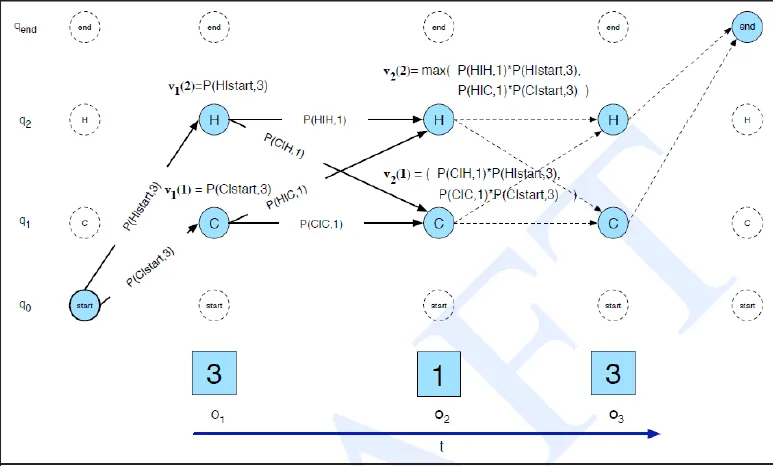
- assume output (observation) is Blue Blue Red (BBR)
- Forward: P(BBR|model) = 0.0792 (SUM of all possible states' probability)
![]()
- Forward: P(BBR|model) = 0.0792 (SUM of all possible states' probability)

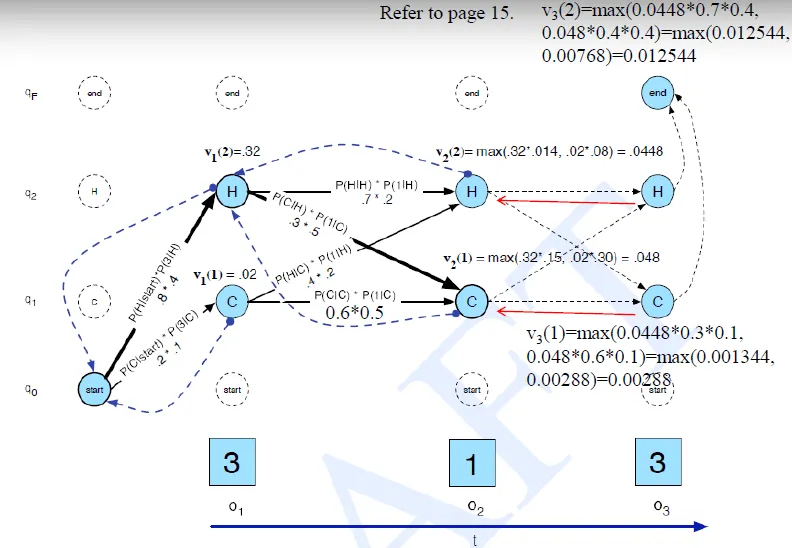
Viterbi
-
compute the most possible path
-
$v_t(i)$ = most possible path probability from time = 0 to time = t, and state = qi at time = t
![]()
-
![]()
-
![]()
-
Viterbi in Urn example
![]()
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}]
path = {}# Initialize base cases (t == 0) for y in states: V[0][y] = start_p[y] * emit_p[y][obs[0]] path[y] = [y] # Run Viterbi for t > 0 for t in range(1,len(obs)): V.append({}) newpath = {} for y in states: (prob, state) = max([(V[t-1][y0] * trans_p[y0][y] * emit_p[y][obs[t]], y0) for y0 in states]) # ↑ find the most possible state transitting to given state y at time=t V[t][y] = prob newpath[y] = path[state] + [y] # newpath(at time t) can overwrite path(at time t-1) path = newpath (prob, state) = max([(V[len(obs) - 1][y], y) for y in states]) return (prob, path[state])



Backward
- Useful for parameter estimation
Description
- Backward variables β, which are the total probability of seeing the rest of the observation sequence($O_t to O_T$) given state qi at time t
![]()
![]()
- 初始化β:令t=T時刻所有狀態的β為1
- 由後往前計算
![]()
- 如果要計算某observation的概率,只需將t=1的後向變量相加

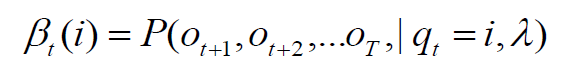
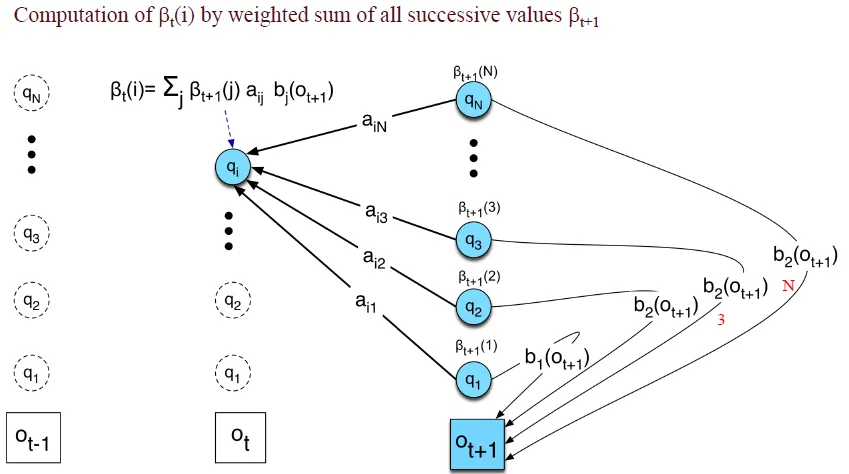
Backward-Forward
- We can locally maximize model parameter λ, by an iterative hill-climbing known as Baum-Welch algorithm(=Forward-Backward) (by EM Algorithm structure)
Forward-Backward Algorithm
- find which** state transitions(A matrix)** and symbol observaions(B matrix) were probably used the most
- By increasing the probability of those, we can get a better model which gives a higher probability to the observation sequence
- transition probabilities and path probabilities are both require each other to calculate
- use A matrix to calculate path probabilities
- need path probabilities to update A matrix
- use EM algorithm
EM algorithm (Expectation-Maximization)
- 迭代算法,它的最大優點是簡單和穩定,但容易陷入局部最優
- (隨機)選擇參數λ0,找出在λ0下最可能的狀態,計算每個訓練樣本的可能結果的概率,再重新估計新的參數λ。經過多次的迭代,直至某個收斂條件滿足為止
- Urn Example
- update transition matrix A ($a_{12}, a_{11}$ ... )
![]()
- P(1→2) = 0.0414
![1→2]()
- P(1→1) = 0.0537
![1→1]()
- normalize: P(1→2)+P(1→1) = 1, P(1→2) = 0.435 ...
- P(1→2) = 0.0414
- 若state數目多的時候,計算量過大…
- 用backward, forward
- 前面用forward, 後面用backward
![]()
- update transition matrix A ($a_{12}, a_{11}$ ... )


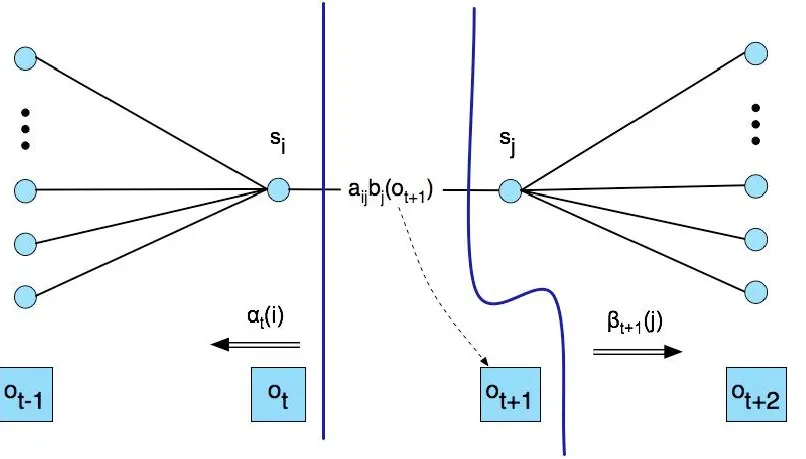
Combine forward and backward
- Let ξt be the probability of being in state i at time t and state j at time t+1, given observation and model λ
![]()
- use not-quite-ξ to get ξ
![]() because
because ![]()
- P(O|λ) → problem1 of HMM 的答案 → 用forward解
- 見上方backward, forward同時使用之圖
![]()
- ξ可用來計算transition matrix
![]()
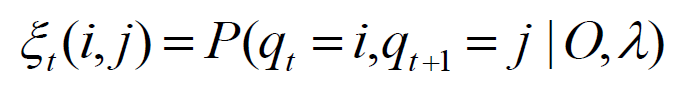
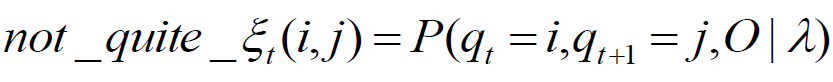 because
because 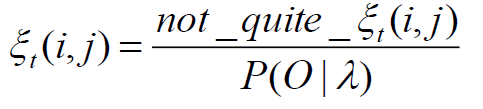
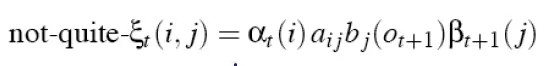
Summary of Forward-Backward 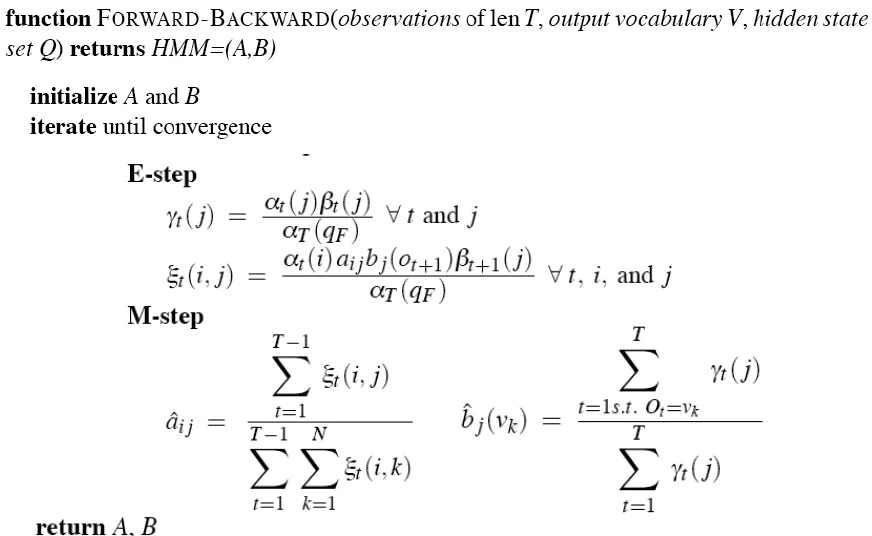
- Initialize λ=(A,B)
- Compute α, β, ξ using observations
- Estimate new λ’=(A,B)
- Replace λ with λ’
- If not converged go to 2
Chap07 Part-of-Speech Tagging
alias: parts-of-speech, lexical categories, word classes, morphological classes, lexical tags
- Noun, verb, adjective, preposition, adverb, article, interjection, pronoun, conjunction
- preposition(P)
- of, by, to
- pronoun(PRO)
- I, me, mine
- determiner(DET)
- the, a, that, those
Usage
-
Speech synthesis
-
Tag before parsing
-
Information extraction
-
Finding names, relations, etc.
-
Machine Translation
-
Closed class
- the class that is hard to add new words
- Usually function words (short common words which play a role in grammar)
- prepositions: on, under, over,…
- particles: up, down, on, off, …
- determiners: a, an, the, …
- pronouns: she, who, I, …
- conjunctions: and, but, or, …
- auxiliary verbs: can, may should, …
- numerals: one, two, three, third, …
-
Open class
- new ones can be created all the time
- For English: Nouns, Verbs, Adjectives, Adverbs
Choosing Tagset: Ex. “Penn TreeBank tagset”, 45 tag
Methods for POS Tagging
- Rule-based tagging
- ENGTWOL: ENGlish TWO Level analysis
- Stochastic: Probabilistic sequence models
- HMM (Hidden Markov Model)
- MEMMs (Maximum Entropy Markov Models)
- Transformation-Based Tagger (Brill)
Rule-Based Tagging
- Assign all possible tags to each word
- Remove tags according to set of rules
- Typically more than 1000 hand-written rules
Hidden Markov Model tagging
- special case of Bayesian inference
- Foundational work in computational linguistics
- related to the “noisy channel” model that’s the basis for ASR, OCR and MT
- Decoding view
- Consider all possible sequences of tags
- choose the tag sequence which is most possible given the observation sequence of n words w1…wn
- Generative view
- This sequence of words must have resulted from some hidden process
- A sequence of tags (states), each of which emitted a word
- $t^n_1$(t hat), which is the most possible tag
![]()
- use viterbi to get tag
![]()
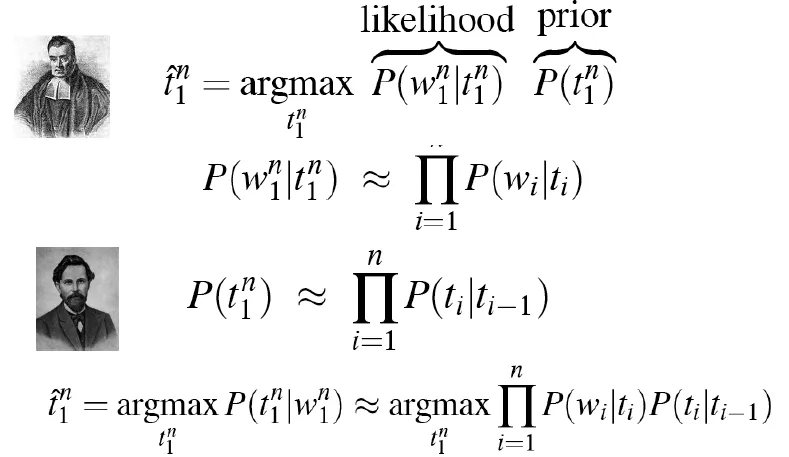
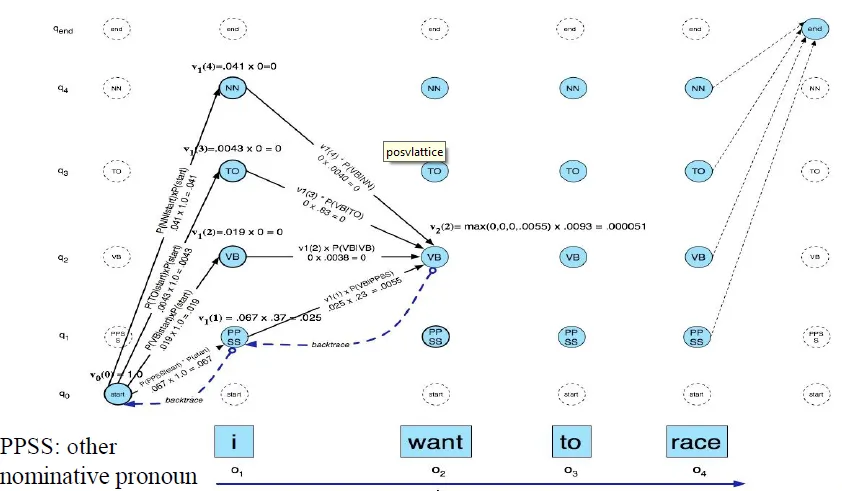
Evaluation
- Overall error rate with respect to a gold-standard test set
- Error rates on particular tags/words
- Tag confusions, Unknown words...
- Typically accuracy reaches 96~97%
Unknown Words
- Simplest model
- Unknown words can be of any part of speech, or only in any open class
- Morphological and other cues
- ~ed: past tense forms or past participles
Maximum entropy Markov model (MEMM)
Maximum Entropy Model
- MaxEnt: multinomial(多項式) logistic regression
- Used for sequence classification/sequence labeling
- Maximum entropy Markov model (MEMM)
- a common MaxEnt classifier
Exponential(log-linear) classifiers
- Combine features linearly
- Use the sum as an exponent
![]()
- Example
![]()
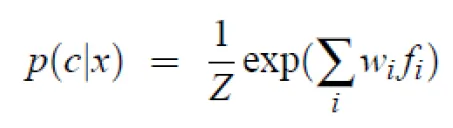

Maximum Entropy Markov Model
- MaxEnt model
- classifies a observation into one of discrete classes
- MEMM
- augmentation(增加) of the basic MaxEnt classifier
- assign a class to each element in a sequence
POS tagging from MaxExt to MEMM
- include some source of knowledge into the tagging process
- The simplest approach
- run the local classifier and feature is classifier from the previous word
- Flaw
- It makes a hard decision on each word before moving on the next word
- cannot use information from the later words
discriminative model(判別模型)
- Compute the posterior P(Tag|Word) directly to decide tag
![]()
- 求解條件機率分佈 P(y|x) 預測 y → 求P(tag|word)來取得tag
- 不考慮聯合機率分佈 P(x, y)
- 對於諸如分類和回歸問題,由於不考慮聯合機率分佈,採用判別模型可以取得更好的效果
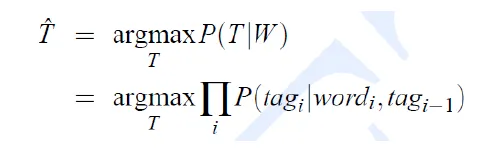
HMM and MEMM(順推和逆推的差別) 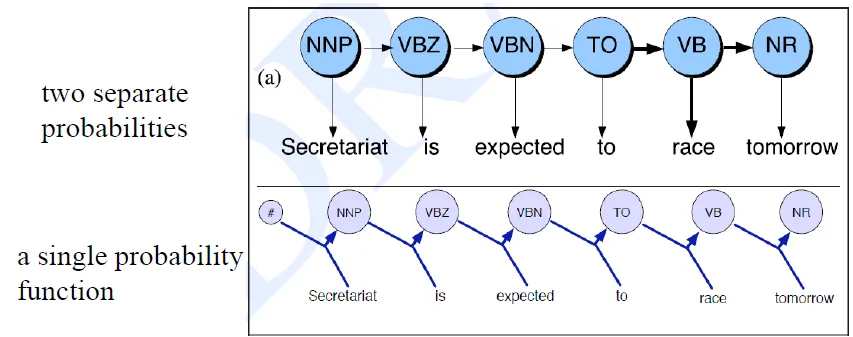
- Unlike HMM, MEMM can condition on any useful feature of observation
- HMM: state is the fiven value
- MEMM: observation is the given value
- viterbi function for MEMM
![]()
![]()
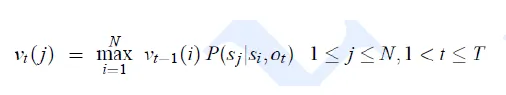
Transformation-Based Learning of Tags
- Tag each word with its most frequent tag
- Construct a list of transformations that improve the initial tag
- trigger environment: at the limited number of words before/after
![]()
![]()
- Trigger by tags
- Trigger by word
- Trigger by morphology(詞法學)
<! -- 分水嶺:尚未分類====== -->
Zipf’s Law (long tail phenomenon)
a word’s frequency is approximately inversely proportional to its rank in the word distribution list
單詞出現的頻率與它在頻率表裡的排名成反比:
頻率最高的單詞出現的頻率大約是出現頻率第二位的單詞的2倍
Jelinek-Mercer Smoothing
interpolate(插值) between bigram and unigram
because if p(eat the) = 0 and p(eat thou) = 0
it still must consider that p(eat the) > p(eat thou)
because p(the) > p(thou)
so p(eat the) = N * p(the | eat) + (1-N) * p(the | thou)
Language Model: Applications
Query Likelihood Model
given a query 𝑞, rank the probability 𝑝(𝑑|q)
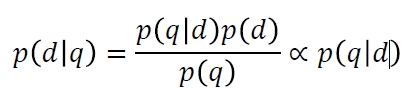
So the following arguments are equivalent:
1.𝑝𝑑𝑞: find the document 𝑑 that is most likely to be relevant to 𝑞
2.𝑝𝑞𝑑: find the document 𝑑 that is most likely to generate the query 𝑞
Typically, unigram LMs are used in IR(information retrieval)
Retrieval does not depend that much on sentence structure
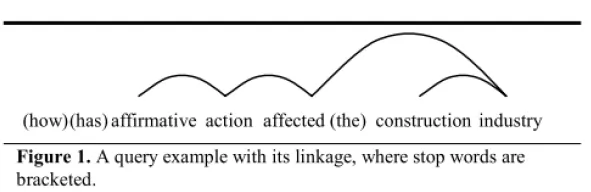
Dependence Language Model
Relax the independence assumption of unigram LMs
Do not assume that the dependency only exist between adjacent words
Introduce a hidden variable: “linkage” 𝐿
Ex.
skipped....
Proximity Language Model
Proximity: how close the query terms appear in a document
the closer they are, the more likely they are describing the same topic or concept
Positional Language Model
Position: define a LM for each position of a document, instead of the entire document
Words closer to a position will contribute more to the language model of this position
Speech Recognition
- The “origin” of language models
- used to restrict the search space of possible word sequences
- requires higher order models: knowing previous acoustic is important!
- Speed is important!
- N-gram LM with modified Kneser-Ney smoothing is extensively used
Machine Translation (MT)
- Decoding: given the probability model(s), find the best translation
- Similar role as in speech recognition: eliminate unlikely word sequences
- Higher order Kneser-Ney smoothed n-gram LM is widely used
- NNLM-style models tend to outperform standard back-off LMs
- Also significantly speeded up in (Delvin et al, 2014)
參考資料
- HHChen 課堂講義
- SDLin 講義
- Stanford NLP course
- 52nlp