Wide And Deep 論文簡介:快思慢想的神經網路版
簡介
Wide And Deep 模型由簡單的Wide模型和複雜的Deep模型組成
- Wide
- Memorization(記憶)
- Generalized linear model(e.g., Linear Regression Model)
- 適合學習稀疏、簡單的規則
- 看了 A 電影的使用者經常喜歡看電影 B,這種「因為 A 所以 B」式的規則
- 從歷史資料學習規則(exploit)
- 讓模型記住大量的直接且重要的規則,這正是單層的線性模型所擅長的
- Memorization(記憶)
- Deep
- Generalization(泛化)
- Embedding-based models(e.g., Deep Neural Network)
- 適合學習通用、深層的規則
- 學習新的特徵組合(explore)
- Generalization(泛化)
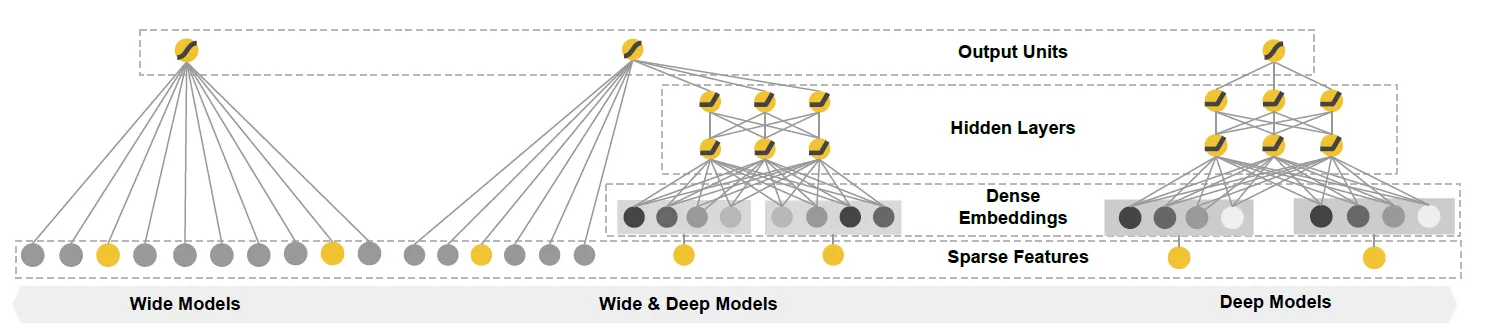
- 合併 Wide and Deep(Jointly Training)
![]()
- 既能快速處理和記憶大量歷史行為特徵,又具有強大的表達能力
- 和 Deep-only 比: 準確率高
- 和 Wide-only 比: 更好的泛化規則
- 當user-item matrix非常稀疏時,例如有獨特愛好的users以及很小眾的items,NN很難為users和items學習到有效的embedding。導致over-generalize,並推薦不怎麼相關的物品。此時Memorization就展示了優勢,它可以「記住」這些特殊的特徵組合
實作
Wide
- $y = w^Tx+b$
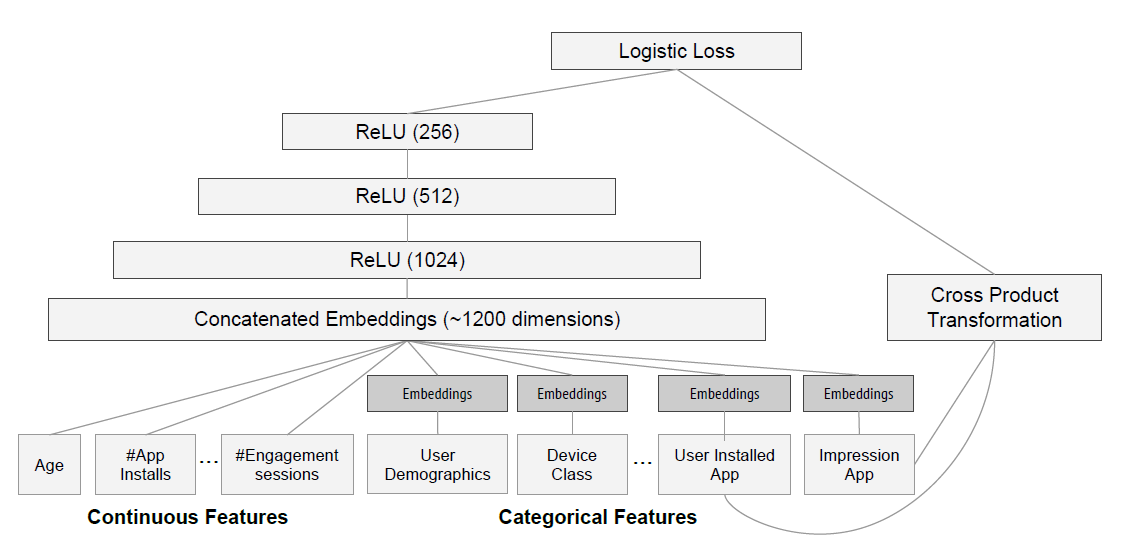
- Cross product transformation
- Optimizer: Follow-the-regularized-leader (FTRL) + L1 regularization
- FTRL with L1非常注重模型的稀疏性。採用L1 FTRL是想讓Wide部分變得更加稀疏
- 但是兩個id類特徵向量進行組合,在維度爆炸的同時,會讓原本已經非常稀疏的multihot特徵向量,變得更加稀疏。正因如此,wide部分的權重數量其實是海量的。為了不把數量如此之巨的權重都搬到線上進行model serving,採用FTRL過濾掉哪些稀疏特徵無疑是非常好的工程經驗
- FTRL with L1非常注重模型的稀疏性。採用L1 FTRL是想讓Wide部分變得更加稀疏
- Wide的輸入特徵較少
- 只有已安裝app和瀏覽過的app
- 希望能充份發揮Wide記憶能力強的優勢
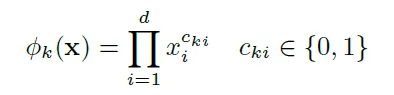
Deep
- 特徵(節錄)
- 用戶特徵
- 年齡、國家、語言
- 行為特徵
- 已安裝App個數
- 已安裝的App
- 情境特徵
- 使用裝置
- 目前時間(星期,小時)
- App特徵
- 發佈時間
- 下載數
- 候選App
- 部份特徵有做embedding(Wide完全沒有)
- 32 dimension
- 用戶特徵
- Optimizer: AdaGrad
Jointly Training
- 同時更新Wide和Deep的權重
- 結構圖
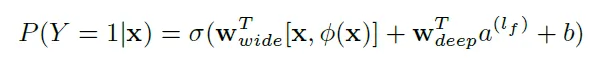
結果
實際用於 Google Play Store App 推薦
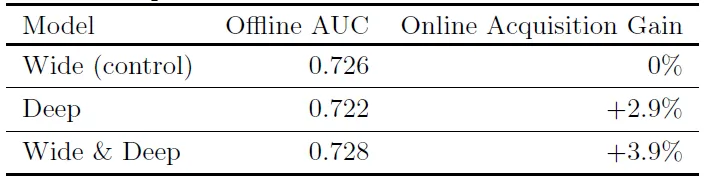
- Deep雖然離線結果較差,但實際結果仍比Wide好
- 深層模型有學習到使用者的隱含喜好,而非直接記憶規則
心得
這就是快思慢想的神經網路版
Wide處理簡單的規則且省力,Deep處理複雜的規則但費力
和純粹的deep learning相比,適合需要記憶大量簡易規則的情境。如App推薦中,有安裝A就推薦B
Wide and Deep是一個架構,代表Wide模型和Deep模型可以為任意實作,所以衍生出許多變形,如DeepFM, Deep and Cross等
Reference
- Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
- https://medium.com/data-scientists-playground/wide-deep模型-推薦系統-原理-8badacf777f3
- https://zhuanlan.zhihu.com/p/142958834
- https://zhuanlan.zhihu.com/p/53361519