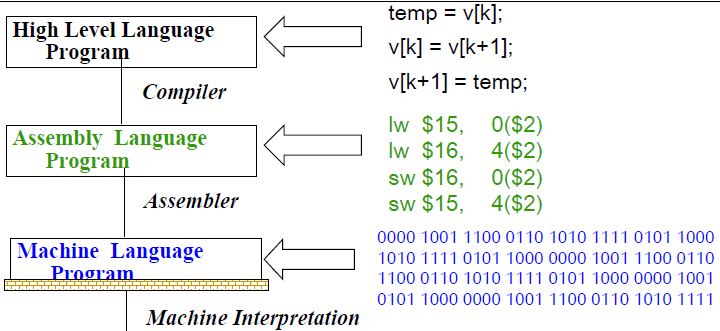
計算機結構(上)
Chap01 Introduction
What can we learn
- How programs finally executed on hardware
- How to write an efficient program
- How hardware and software work well together
- How to improve hardware performance
![]()
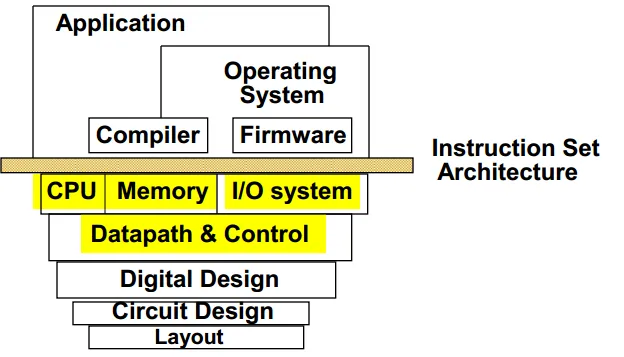
What really matters is the functioning of the complete system, hardware, runtime system, compiler, operating system, and application
“In networking, this is called the “End to End argument” --- H&P
Why need to take this course
You will be able to answer the following questions:
Q1: How can I write a program with good performance?code B perform better than code A?
(I don't know why)
Code A
for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)
{r = 0;
for (k = 0; k < N; k = k+1)
{
r = r + y[i][k]*z[k][j];
};
x[i][j] = r;
};
========
Code B
for (jj = 0; jj < N; jj = jj+B)
for (kk = 0; kk < N; kk = kk+B)
for (i = 0; i < N; i = i+1)
for (j = jj; j < min(jj+B-1,N); j = j+1)
{
r = 0;
for (k = kk; k < min(kk+B-1,N); k = k+1)
{
r = r + y[i][k]*z[k][j];
}
x[i][j] = x[i][j] + r;
};
Q2: CPU frequency ? Performance
Ans at Chap02
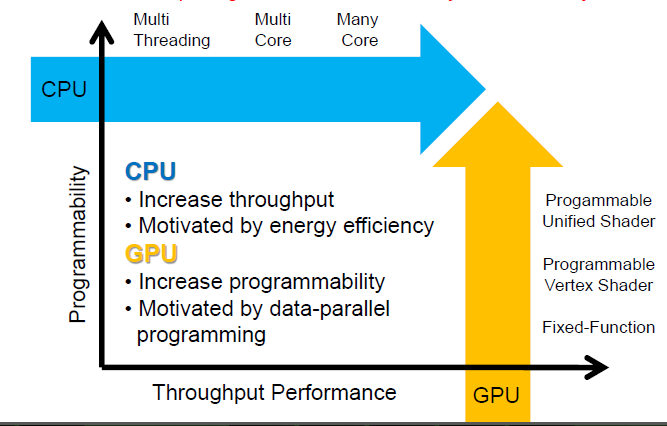
Q3: Why do Nvidia GPUs get so much attention today?
Heterogeneous(異質) Computing : Integrated CPU/GPU
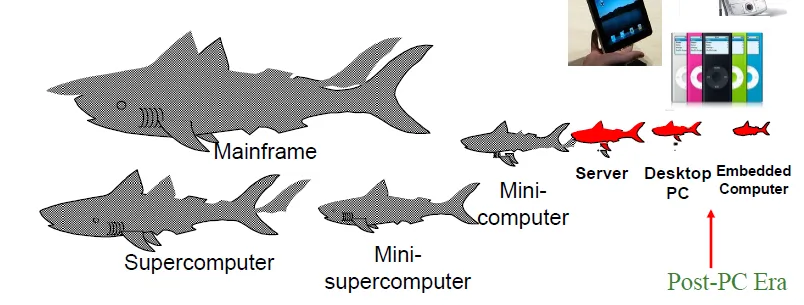
Post PC Era
資訊界:小魚吃大魚
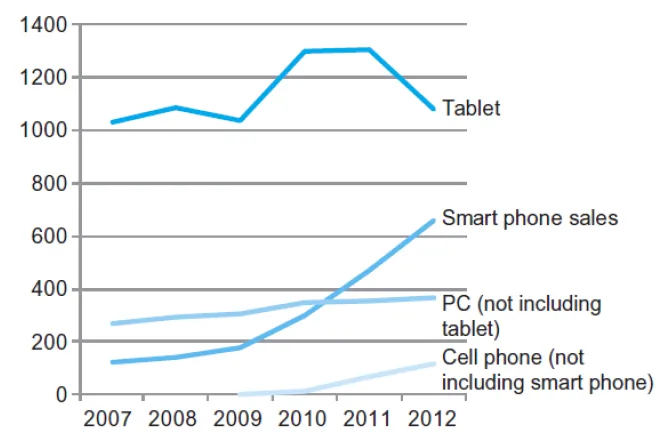
Ex. Cloud computing
- Software as a Service (SaaS)
- Amazon and Google
Chip War: Big core or Small core
Workload changes in data centers
Past: databases, financial services
Now: web service, cloud computing (accessing mails, photos, facebooks, etc)
=> Simple tasks & large amount of parallel tasks
=> Small Core is better
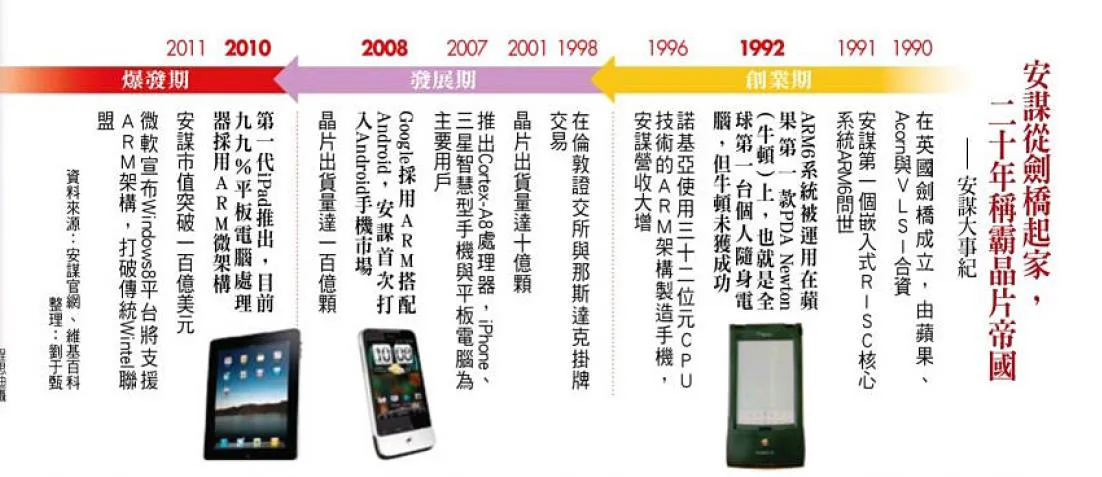
Ex. ARM
- Founded at the year of 1990, in Cambridge, England
- Co-founded by Apple & Acron
- Emphasize low-power since day one
- First low-power, 32 bit mobile processor
- sells designs(IP license) instead of chips
![]()
![]()
Inside the Processor (CPU)
-Datapath: performs operations on data
-Control: sequences datapath, memory, ...
-Cache memory
-Small fast SRAM memory for immediate access to data
Moore’s Law (1965)
- Gordon Moore, Intel founder
- “The density of transistors in an integrated circuit will double every year.”
- Reality
- The density of silicon chips doubles every 18 months
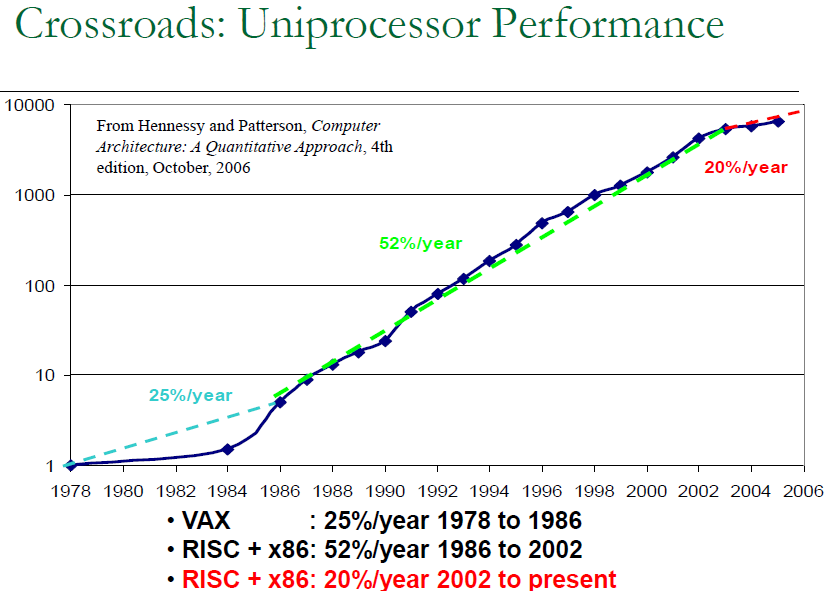
Uniprocessor Performance
VAX : 25%/year 1978 to 1986
RISC + x86: 52%/year 1986 to 2002
RISC + x86: 20%/year 2002 to present
Concept Change
- Power expensive,** Transistors free** (Can put more on chip than can afford to turn on)
- so hot that make low efficiency
- law of diminishing returns(收益遞減) on more HW for ILP( Instruction Level Parallelism, 指令層級平行)
- 愈平行,效率提升的投資投酬愈少(control overhead)
- Memory slow,** CPU fast** (200 clock cycles to DRAM memory, 4 clocks for multiply)
- Power Wall + ILP Wall + Memory Wall = CPU Wall
- Uniprocessor performance 2X / 1.5 yrs -> multiple cores (2X processors per chip / 2 years)
CPU constrained by power, instruction-level parallelism, memory latency
CPU history
8086 Introduced x86 ISA 1978
80286 Virtual memory 1982
80386 32-bit processor (1985)
80486 Pipelining Floating point unit 8 KB cache (1989)
Pentium Superscalar (1993)
Pentium Pro / II / III Dynamic execution Multimedia instructions 1995-9
Pentium 4 HyperThreading Deep pipeline (2001)
Pentium D (2005) Dual core 2 Pentium 4 cores
AMD big.LITTLE 大核+小核
AMD big.LITTLE
8 Design Principle for Computer Architecture/System
- Design for Moore’s Law
- Use abstraction to simplify design
- Make the common case fast
- Performance via parallelism
- Performance via pipelining
- Performance via prediction
- Hierarchy of memories
- Dependability via redundancy(多餘使其安全)
Chap02 Performance/Power/Cost
How to measure, report, and summarize performance/power/cost?
- Metric(度量)
- Benchmark(基準)
Two Notions of “Performance”
- Response Time (latency)
- Throughput
-> We focus on response time
Metrics for Performance Evaluation
- Program execution time(Elapsed time經過時間)
- Total time to complete a task, including disk access, I/O, etc
- CPU execution time(使用CPU的時間)
- doesn't count I/O or time spent running other programs
- Our Focus: user CPU time(without system CPU time)
- time spent executing the lines of code that are "in" program
performance(x) = 1 / execution_time(x)
For Embedded System
- Hard real time
- A fixed bound on the time to respond to or process an event
- Soft real time(寬鬆)
- An average response or a response within a limited time
CPU performance
CPU time
= CPU clockcycles x Clockcycle time
= CPU clockcycles / clockrate
(Because Clock Cycles = Instruction Count x Cycles per Instruction )
= Instruction Count x Cycles per Instruction x Clockcycle time
Instruction Count of program is determined by program, ISA and compiler
cycles per instruction is determined by CPU hardware
different instruction may have different CPI(Clocks Per Instruction)
-> use weighted average CPI(加權平均)
Aspects of CPU Performance
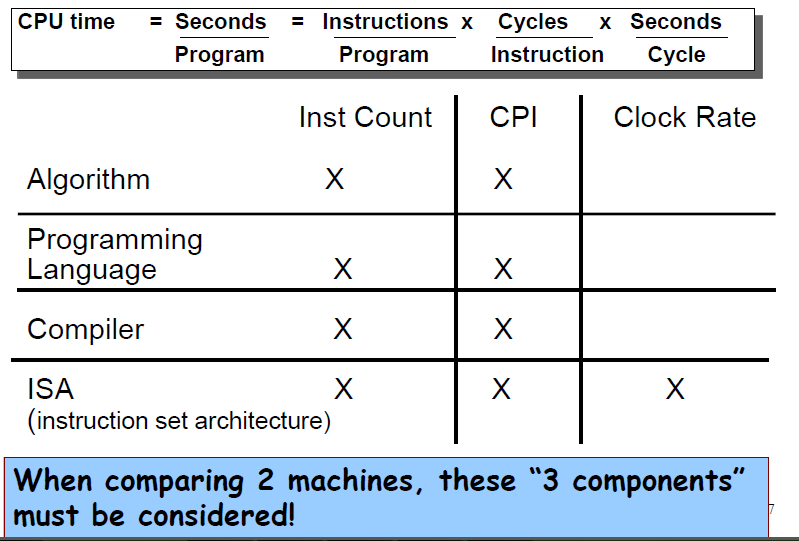
Chap01 Q2: CPU frequency(時脈) is not fully related to performance
MIPS
- Millions of Instructions Per Second
- = Clock Rate / (CPI * 10^6)
- Can't be performance metric(CPI varies between programs)
CMOS IC power performance

$V ∝ Frequency$ => $power ∝ V^3$
high ascending rate
dynamic energy: energy that is consumed when transistors switch states from 0 to 1 and vice versa. It depends on the capacitive loading of each transistor and the voltage applied:
Energy ∝ Capacitive load x Voltage^2
Why is Multi-Core Good for Energy-Efficiency?
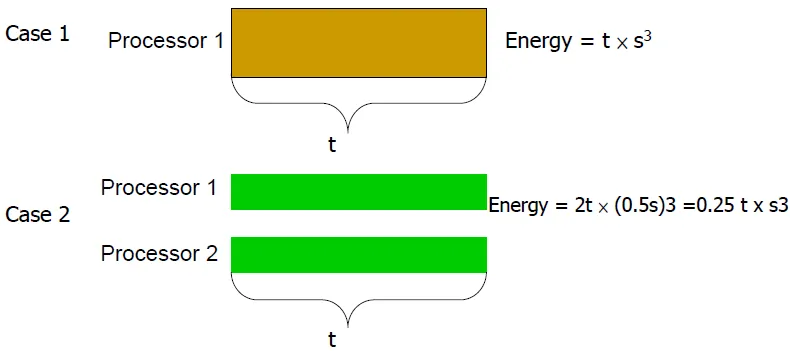
only use 1/4 power
Requires explicitly parallel programming. Hard to do because
- Programming for performance
- Load balancing
- Optimizing communication and synchronization
Manufacturing ICs
Yield(良率): proportion of working dies(晶片) per wafer
Nonlinear relation to area and defect rate
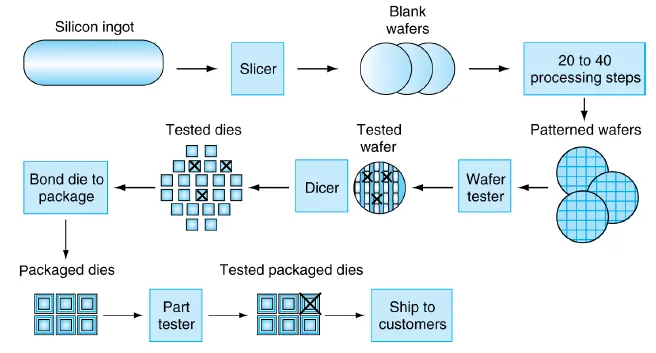
Benchmark
SPEC benchmark
- Standard Performance Evaluation Corp. (SPEC)
- Develops benchmarks for CPU, I/O, Web, …
- CPU Benchmark
- Programs to simulate actual workload
- focuses on CPU performance(a little I/O)
- Test both integer and floating point applications
CINT (integer) and CFP (floating-point)
SPECRatio
Normalize execution times to reference computer
performance = time on standard computer/ time on computer being rated

Since ratios, geometric mean is proper
Power Benchmark
- Power consumption of server at different workload levels(不同的工作量下,平均的工作效能)
- Report power consumption of servers at different workload levels, divided into 10% increments
- Performance: ssj_ops/sec(每秒完成的事務數)
- Power: Watts (Joules/sec)
![]()
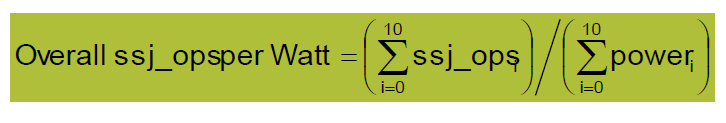
Amdahl’s Law
程式的平行化只能將執行時間縮短到一定程度(因為分散運算的overhead)

Low Power at Idle(x)
- At 100% load: 295W
- At 50% load: 246W (83%)
- At 10% load: 180W (61%)
- not porportional!
=> In general, the more load, the better power consumption rate
=> Consider designing processors to make power proportional to load
Chap03 Instruction Set Architecture(ISA)
Definition: Instruction set provides an layer of abstraction to programmers
ISA Design Principle
makes it easy to build the hardware and the compiler while maximizing performance and minimizing cost.
Interface Design
(portability, compatibility, generality)
(convenient at high level , efficient in low level)
Design Principles
- Design Principle 1: Simplicity favors regularity(All operation takes three operands)
- Design Principle 2: Smaller is faster(MIPS only 32 register)
- Design Principle 3: Make the common thing fast(addi)
- Design Principle 4: Good design demands good compromises(妥協)(three format of instruction code)
MIPS Instruction Set
Stanford MIPS be Memory are referenced with byte addresses in MIPScommercialized
a kind of RISC精簡指令集(Reduced Instruction Set Computing)
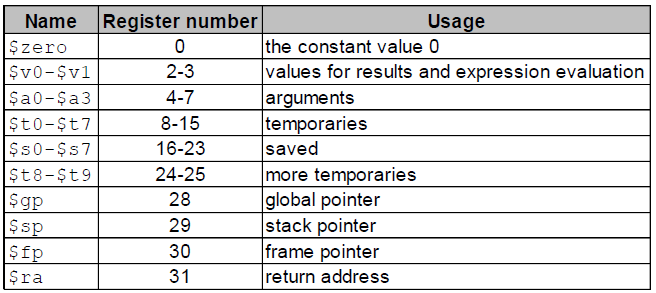
- 31個 32-bit integer registers (R0 = const 0)
![]()
- 32個 32-bit floating-point registers
- 32-bit HI, LO, PC (program counter) -- internal, can't modify
Memory are referenced with byte addresses in MIPS
1 word = 4 byte
| 指令 | 意義 | 備註 |
|---|---|---|
| add Ra Rb Rc | Ra =Rb + Rc | |
| load Ra A | Ra =mem[A] | |
| store Ra A | mem[A] =Ra | Memory are referenced with byte addresses in MIPS |
| Data transfer instructions | ||
| lw $t0, 8 ($s3) | t0 = mem[8+reg[$s3]] | lw dest offset base, offset must be constant |
Ex.  |
||
| sw $t0, 8 ($s3) | mem[8+reg[$s3]]= $t0 | |
| addi $s3, $s3, 4 | add constant value | |
| srl $10, $16, 4 | $t2 = $s0 >> 4 bits | |
| sll $10, $16, 4 | $t2 = $s0 << 4 bits | |
| rs fill 0 because unused | ||
| or $t0, $t1, $t2 | $t0 = $t1 | $t2 | |
| ori $6, $6, 0x00ff | ||
| and $t0, $t1, $t2 | $t0 = $t1 & $t2 | |
| andi $6, $6, 0x0000 | ||
| nor $t0, $t1, $t3 | t0 = ~($t1 | $ t3) |
| (nor $t0, $t1, $t3) = ~($t1), if $t3 = | ||
| ~(A) = 1 if A = 0 | ||
| ~(A) = 0 if A != 0 |
lui $t0, 1010101010101010 # load upper immediate
// that is: 1010101010101010 0000000000000000
mult rs, rt
Multiplying two 32-bit numbers can yield a 64-bit number.
higher 32 bits are stored in HI
lower 32 bits are stored in LO
MFHI rd -- $rd = HI
MFLO rd -- $rd = LO
div rs, rt | rs / rt
Quotient stored in Lo
Remainder stored in Hi
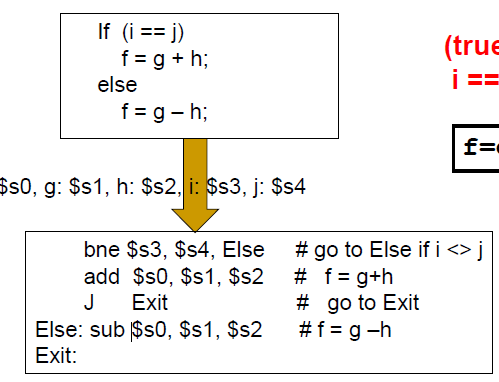
Branch instructions
Conditional branches
beq reg1, reg2, L1
Go to statement L1 if [reg1] == [reg2]
bne reg1, reg2, L2
Go to statement L2 if [reg1] != [reg2]
Unconditional branches
j L1
jr(jump register)
unconditional jump to the address stored in a register
Provides full 32bits address

Use J for calling subroutines
Use Jal for calling functions
Use Jr for ending a subroutine by jumping to the return address (ra)
slt reg1, reg2, reg3
=> if reg1 = (reg2 < reg3) ? 1 : 0;
move copies a value from one register to another
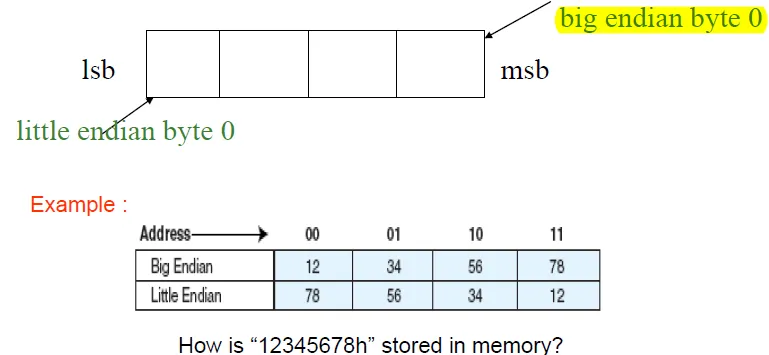
Byte order: Big Endian vs. Little Endian
Big endian(順序, 一般數字寫法): byte 0 is most significant bits e.g., IBM/360/370, Motorola 68K, MIPS, Sparc, HP PA
Little endian(逆序): byte 0 is least significant bits e.g., Intel 80x86, DEC Vax, DEC Alpha
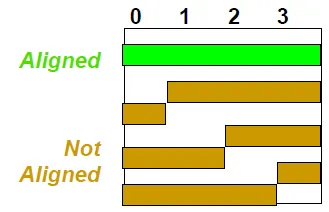
Alignment
object on the address that is multiple of their size(一次讀取大小的倍數)
Stored-Program Concept
Computers built on 2 key principles:
- Instructions are represented as numbers
- entire programs can be stored in memory to be read or written just like numbers
Shift is faster than multiplication
=> Multiplying by 4 is the same as shifting left by 2:
•Fetch instruction from mem [PC]
•without decision making instruction
•next instruction = mem [PC + instruction_size]
MIPS Instruction Format
instruction code - 32bit
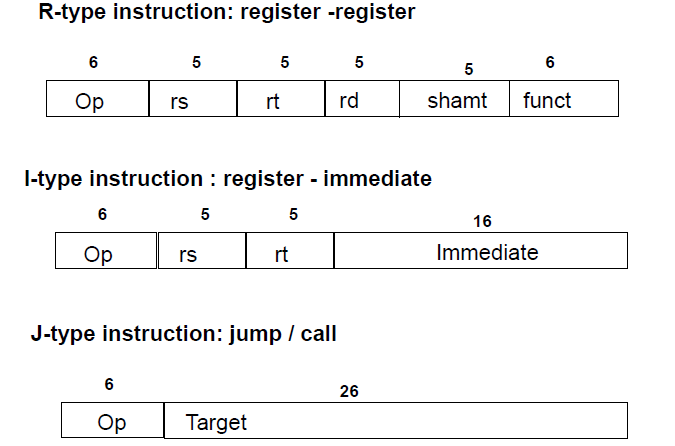
R-type
- rs, rt = source register, rd = destination register
- 32個register => 5bit
- shamt: shift amount
- filling 0 when unused
- func: function field(same operate code with different function code can looked as different argument)
- Ex.
add,addu,addi
- Ex.
I-type
for those have constant argument(immediate value)
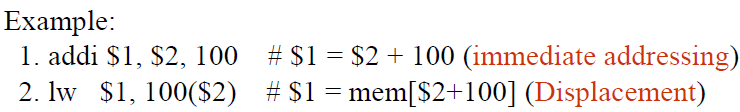
first example, rs = $2(source) rt = $1(destination)
PC addressing mode
New PC = PC + 4(auto go to next instruction) + Immediate x 4
if want to jump farther than 16bit
bne s1 s2 L2
jump L1 # equals to beq s1 s2 L1, but jump can go farther
L2:
J-type
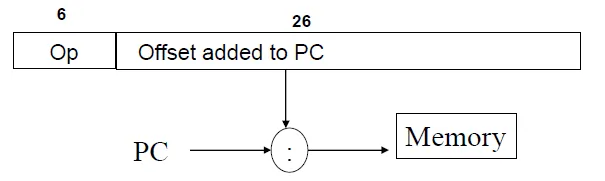
goto absolute address(I-type is relative address)
equal to immediate in the middle of the program counter address

指令表
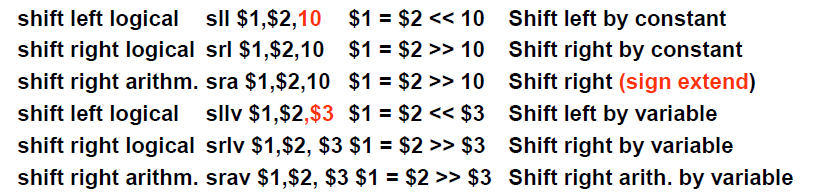


function
pass value
-
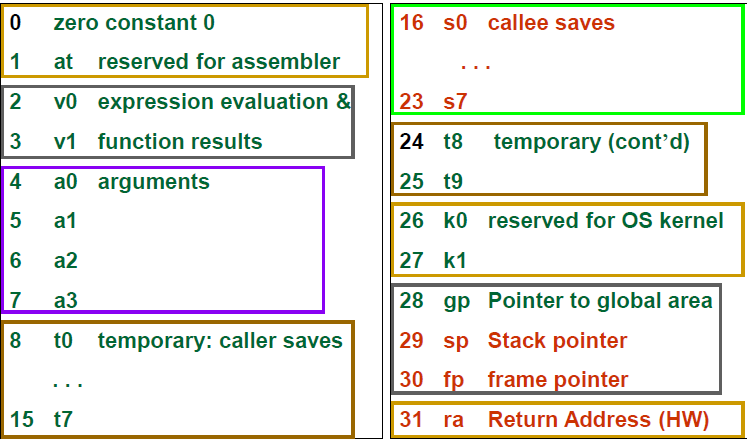
$a0 ~ $a3 : 4 arguments
- if # of parameters is larger than 4 – store to the stack
-
$v0 ~ $v1 : 2 return values
preserve register values of caller -
stack
Caller-save register
- Caller saved register: 由Caller負責清理或存入stack frame
- hold temporary quantities that need not be preserved across calls
- Caller先備份,所以callee便可直接使用caller-save register
- $t0~t7
- Callee saved register: 由Callee負責清理或存入stack
- hold values that should be preserved across calls(caller還需要用, callee用的時候要先備份)
- callee should save them and restore them before returning to the caller
- $s0~s7
call function: jal procedure_address (jump and link)
- Store the return address (PC + 4) at $ra
- set PC = procedure_address
return : jr $ra
Frame pointer points to the first word of the procedure frame
procedure call stack
Memory layout
- text: code
- static data: global variable
- $gp is the offset of static data
- dynamic data: heap
- malloc, new
- stack: automatic storage
Caller Steps
- pass the argument $a0,$a1
- save caller-saved registers
- jal
Callee Steps
- establish stack frame $sp
subi $sp, $sp - saved callee saved registers
Ex. $ra, $fp, $s0-$s7 - establish frame pointer $fp
Add $fp, $sp,-4 - Do Something
- put returned values in $v0, $v1
- restore(load) callee-saved registers
- pop the stack
- return: jr $ra
ASCII (American Standard Code for Information Interchange)
8 bits/character
`lb sb`
Unicode (Universal Encoding)
16 bits/character
`lf sf`
performance
1 | Clear1(int array[ ], int size) |
Clear2 > Clear1
pointer is faster than fetching value
1 | move $t0, $a0 # p = &array[0] |
Synchronization
SWAP: atomically interchange a value in a register for a value in memory; nothing else can interpose itself between the read and the write to the memory location
1 | $S4 = 1; |
Load linked: load value from rs(atomic)
`ll rt offset(rs)`
Store conditional
`sc rt offset(rs)`
if location not changed since the ll , rt return 1, 否則回傳 0
1 | swap s4 and s1 |
MIPS Addresssing Mode
- Register addressing
運算對象在register
add - Immediate addressing
運算對象是constant
addi - Base addressing(The argument is at MEM)
運算對象在memory
lw
way to get address
1.
.data # define data
xyz:
.word 1 # some data here
…
.text # program code
…
lw $5,xyz # equals to lw $5, offset($gp)
2.
la $6, xyz # $6 = &xyz - PC-relative addressing
beq - Pseudodirect addressing
j 100
from program to memory
Program -----------> assembly ---------> object file:
compiler assembler
machine language module + library module --------->
linker
machine code program ---------> memory
loader
Assembler
Symbol table: translate variables into memory address
Psudoinstruction: common variation of assembly language instructions
Linker
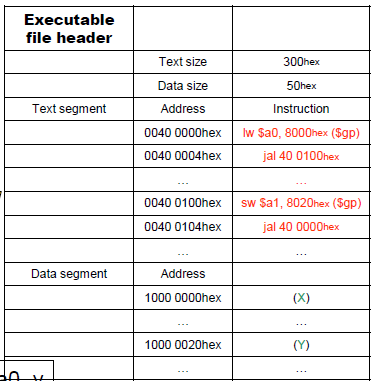
generate executables file header
- Place code and data modules symbolically in memory.
- Determine the addresses of data and instruction labels.
- Patch both the internal and external references
Loader
determine the size of the text and data segment
Creates an address space
Copies the instructions and data to memory
Initializes the machine registers and sets the stack pointer
Jump to a start-up routine
Dynamically Linked Libraries (DLL)
Loading the whole library even if all of the library is not used => libraries are not linked and loaded until the program is run, and use lazy procedure linkage
java
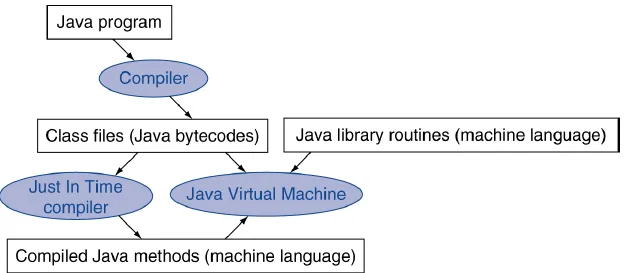
Java bytecode: use instruction set designed to interpret Java programs
Just In Time Compiler (JIT): compiler that operates at runtime, translating bytecodes into the native code of the compiler
Java Virtual Machine (JVM): The program that interprets Java bytecodes
ARM
AMD64 (2003): extended architecture to 64 bits
AMD64 (announced 2007): SSE5 instructions
Intel declined to follow...
Similar to MIPS
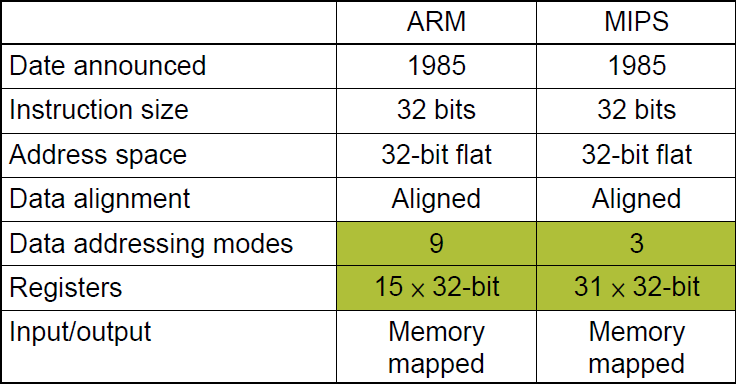
do anything for code density
include
32-bit ARM instruction
16-bit Thumb instruction
8-bit Java Instruction Set
Current program status register: Top four bits of CPSR
use for performance
N : Negative
Z : Zero
C : Carry
V : Overflow
Conditional execution
ADDEQ r0,r1,r2 => r1-r2, If zero flag set then do r0 = r1 + r2
Intel x86 ISA
History: skipped
| IA-32 | MIPS |
| -------------------------- | --------------- | ----------------- |
| RISC | RISC |
| general purpose register | 8 | 32 |
| operand operation | 2 or 3 | 3 |
| operations to be performed | Register-memory | register-register |
| addressing modes | more | less |
| encoding | variable-length | fixed-length |
simple instruction -> higher performance
because complex instructions are hard to implement, slow down all instructions
assembly code for high performance(x)
More lines of code -> more errors and less productivity
Chap04 Building Single-Cycle Datapath and Control Unit
How to Design a Processor
- Analyze instruction set => datapath(include PC,... functional units) requirements
- Select set of datapath components and establish clocking methodology
- Assemble datapath
- Analyze implementation of each instruction to determine control points
- Assemble the control logic
Details
register-tranfer暫存器傳輸
RTL (Register Transfer Languages)
Ex. ADDUR[rd] <–R[rs] + R[rt], PC <–PC + 4
2.
Combinational Elements: outputs only depend on input
Ex. ALU, MUX, Adder
Storage Elements: outputs depend on input and state(clock)
Ex. Flip-Flop, register, memory
Register
Edge-triggered clocking
until next edge would the value change
3.
Instruction Fetch Unit: mem[PC]
Sequential code
PC <- PC + 4
Branch and Jump
PC <- Target addr
Memory Operations
Mem[R[rs] + SignExt[imm16]]
sign extension: increasing the number of bits without changing value (Ex. 10 0010 -> 0010 0010)
4.
Control Unit: set control flag to change the operation with the change of operation code
Control Flags
- MemWr: write memory
- MemtoReg: 0 => use ALU output 1 => use Mem value
- RegDst: 1 => “rd” when 3 operand are all register; 0 => “rt”
- RegWr: write to register
- ALUsrc: 1=> immed; 0=>regB
- ALUctr: “add”, “sub”
- PCSrc: 1=> PC = PC + 4; 0=> PC = branch target address
| instruction | MemWr | MemtoReg | RegDst | RegWr | ALUsrc | ALUctr | PCSrc |
|---|---|---|---|---|---|---|---|
| Add | 0 | 0 | 1 | 1 | 0 | add | 1 |
| Load | 0 | 1 | 0 | 1 | 1 | add | 1 |
| Store | 1 | x | x | 0 | 1 | add | 1 |
| Branch | 0 | x | x | 0 | 0 | sub | value(after sub) |
| Ori | 0 | 0 | 0 | 1 | 1 | or | 1 |
| Jump | ? |
use k-map to make control flags simple
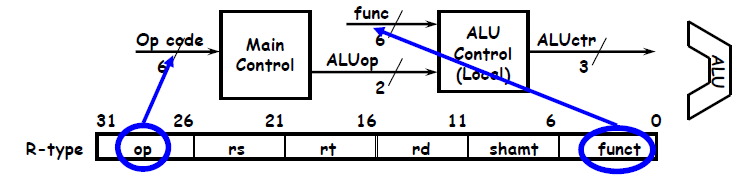
I-type: (00) add for load/store and (01) sub for beqand (10) for ori
R-type: (11, need to check funct field)


Chap05 Pipeline
when CPI=1:
- Load is too slow! -> Long Cycle Time
- Real memory is not so nice as our idealized memory
- cannot always get the job done in one (short) cycle
Pipelining doesn’t help latency of single task, it helps throughput of entire workload
Multiple tasks operating simultaneously using different resources
Pipeline rate limited by slowest pipeline stage
Unbalanced lengths of pipe stages reduces speedup(切平均,增加效能最多)
Break the instruction into smaller steps(5 steps in MIPS):
Execute each step in 1 clock cycle
- Instruction Fetch(Ifetch)
- Instruction Decode and Register Fetch(Reg/Dec)
- Execution, Memory Address Computation, or Branch Completion(Exec)
- Memory Access or R-type instruction completion(Mem)
- Write back to register(Wr)
simplified: IF ID EX MEM WB
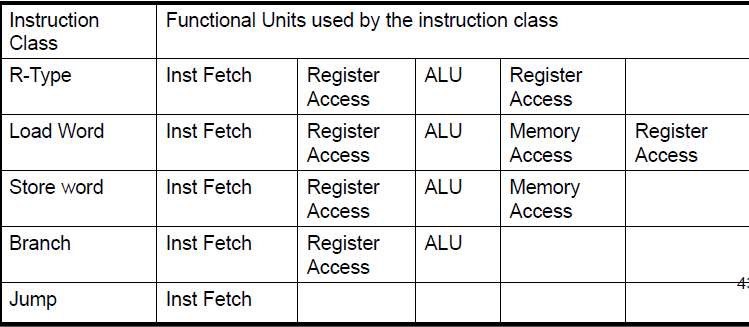
The Four Stages of R-type: without Mem
The Four Stages of store: without Wr
The Three Stages of Beq: without Mem, Wr
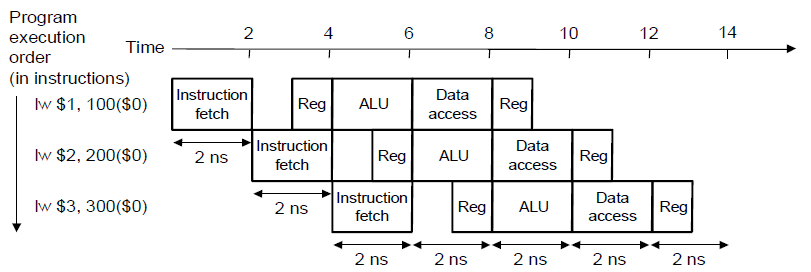
Ideal speedup from pipelining == # of pipeline stages
(分成N段->理想上,速度提升N倍)
Pipeline Hazards
- structural hazards: use the same resource at the same time(Single Memory)
![structure hazard]()
- data hazards: use item before it is ready(load, update)
- control hazards: make a decision before condition is evaluated(branch)
Can always resolve hazards by waiting
Need to detect and resolve hazards
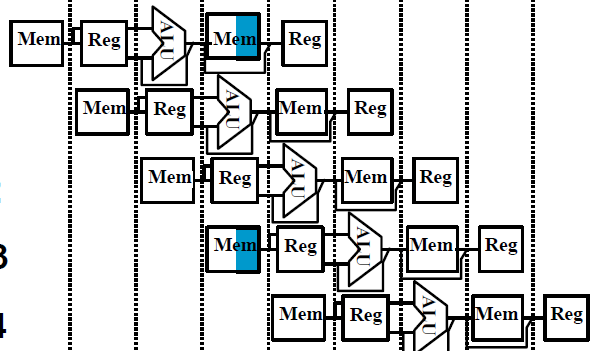
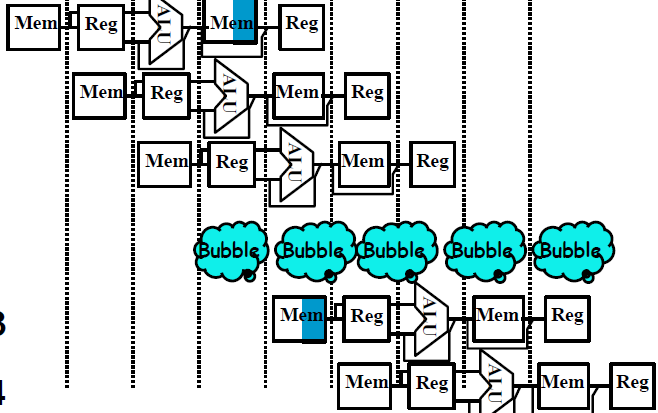
Way to Solve Hazards
- structural
- Stall(put bubbles that do nothing)
![stall]()
- Split instruction and data memory(2 different memories)
- Delay R-type’s Write by One Cycle()
- Stall(put bubbles that do nothing)
- data
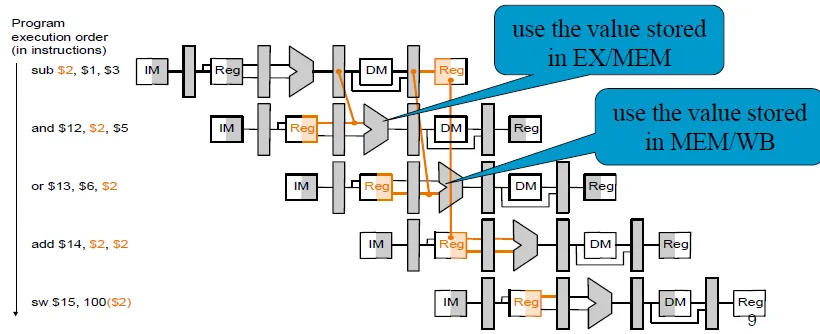
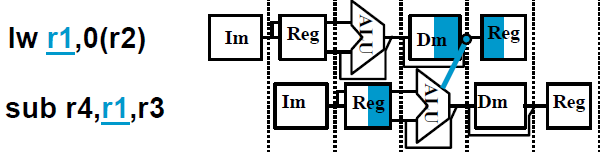
- “Forward” result from one stage to another(算出答案後,在放入記憶體前,就先給之後的instruction使用)(可以同時read and save)
- Load-use data hazard: can't solved by forward, can solved by reordering instructions, otherwise, need stall
![lw hazard]()
![loaduse->forward]()
- control
- stall until the outcome of the branch is known
- solve branch earlier: put in enough extra hardware so that we can test registers, calculate the branch address, and update the PC
- Predict: flush if the assumption is wrong
dynamic scheme: history of branch (90% success) - performance: 13% of branch instructions executed in SPECint2000, the CPI is slowdown of 1.13 versus the ideal case
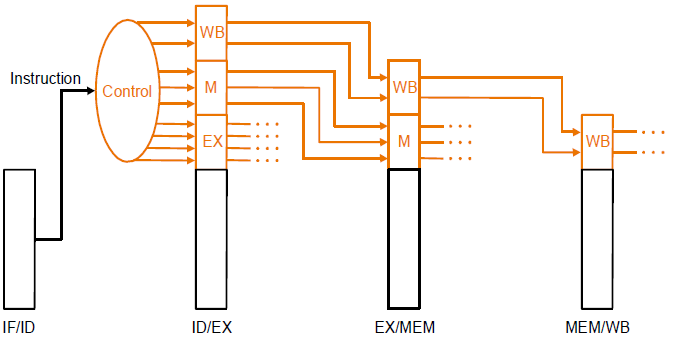
Pipelined datapath
Pipeline registers
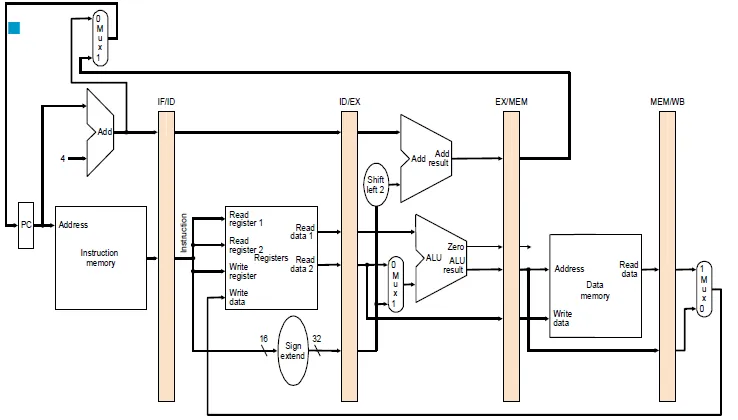
- The registers are named between two stages
control in each stage
Pass control signals along just like the data