計算機結構(下)
Chap07 Pipelining (II)
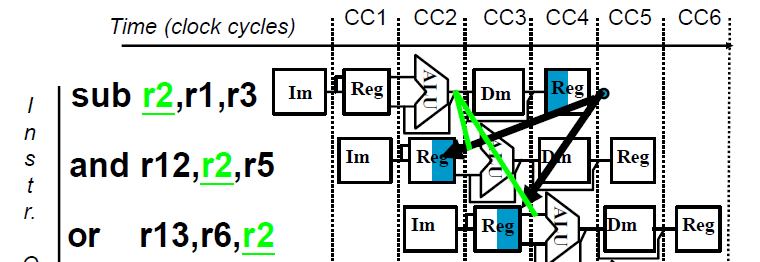
Data Dependence Detection
Hazard conditions:
- EX hazard
- EX/MEM.RegisterRd = ID/EX.Register Rs or Rt
- MEM hazard
- MEM/WB.RegisterRd = ID/EX.RegisterRs or Rt
- Ex/MEM.RegisterRd != ID/Ex.RegisterRs(優先選EX)
- RegWrite == true
- RegisterRd != $0
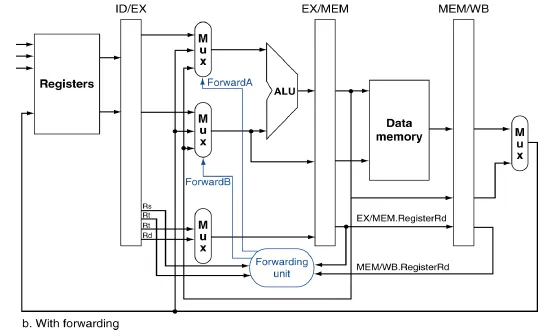
Resolving Hazards by Forwarding
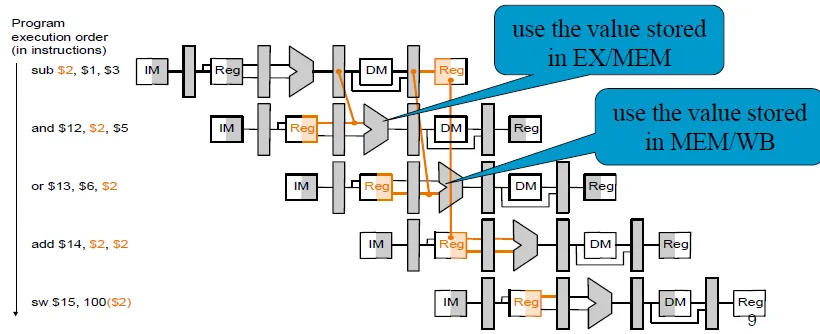
Add MUX to ALU inputs
Forwarding Control in EX
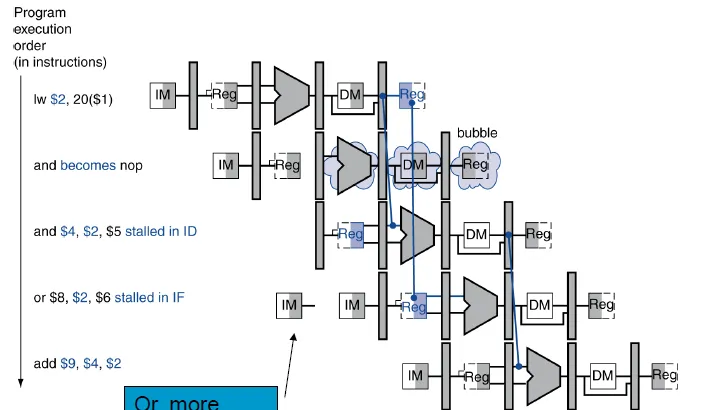
load-use data hazard(instruction after LW) -> stall it
If (ID/EX.MemRead and
((ID/EX.RegisterRt = IF/ID.RegisterRs) or
(ID/EX.RegisterRt = IF/ID.RegisterRt)))
stall the pipeline
Stall: ID/EX裡的control value改成0,使EX MEM WB都不做事(nop) 並防止PC和IF/ID register更新,也就是確保他們下個cycle做跟這個cycle一樣的事
Insert a bubble:空白的instruction, 不做事
Control Hazard Solutions
Branch 有沒有taken可以在MEM確認。如果發現prediction錯誤就重新設定PC,並把control都設為0,flush掉跑錯的instruction。
一個簡單的改進方式就是,在ID stage把資料從register讀出來後加上比較兩個值是否相等的元件,compare完才進到id/ex,這時候提早了一個cycle知道branch是否taken。
當branch發生使用的值在ALU做完運算時,透過forwarding就可以解決了
但如果branch發生在使用的值正在load的話,就必須stall。而如果是一load出來馬上就要做branching的判斷的話,就必須stall 2個cycle

Dynamic prediction的branch history table,以branch instruction的address(取最後n個bit)做索引,並儲存branch的結果。如果猜錯的話就做之前一樣的flush並修改表。
跳出loop時會猜繼續,第一次進入loop會猜跳出 -> 導致錯誤率大幅提高
-> 2bit的predictor, 連續兩個taken/not taken才會改變狀態
但就算猜對,還是要算出target address,所以在branch taken時會有一個cycle的penalty。解決的方法是新增buffer存放branch target address。
Exception
syscall,未定義的opcode,或overflow處理等等(以上為CPU內產生的指令)或是受外部的I/O控制器的干涉。導致performance的降低。
- 完成先前的指令
- Flush the instruction in the IF, ID and EX stages
- 把這些違例或是被干擾的instruction的PC(實際上是PC+4)存在Exception program counter(EPC)
- 問題的跡像(indicator)也存起來,在MIPS中是使用Cause register
- 然後再跳到handler(PC = 0x40000040)
- 另外一種解決的機制是,以硬體等級去告訴I/O handler,根據不同的cause跳去不同的handler(不同的address),instructions要不就去執行interrupt的部份,要不就跳到handler去處理。
- Handler先讀看原因(indicator)然後再轉至專門解決此類問題的handler,然後決定該採取什麼行動,如果是restartable(可以重跑),就用EPC回到原本執行的地方(EPC-4),並採取判斷正確的行動。否則就終止程序並根據EPC cause來回報錯誤。

ILP(instruction level parallelism),指令層級的平行處理。
增進ILP的方法
- Deeper pipeline,把pipeline分成更多stage,而每個stage因為workload相對的比較少,所以可以讓cpu clock cycle變短,進而增進效能
- Multiple issue,有多個pipeline同時進行,所以每個clock cycle都同時跑好幾個instruction。但是互相依賴性(比如說不同pipeline之間的hazard或共用到哪些資源)會使得實際上不是變幾倍的pipeline IPC就變幾倍。
Multiple issue
可以分為static和dynamic。
Static的是由compiler把要同時執行的instruction包成一包一包的instruction packets。
可以把instruction packet想成一個非常長的instruction裡面有好幾個同時運作的operations。這樣的概念叫做VLIW(very long instruction word)
偵測避免hazard
- 把instruction重新排列並包成issue packets時避免會造成hazard的順序。
- 同時在跑的instruction要互相independent不然就會搶資源或造成data hazard。
- 在不同的packets之間,可以有dependency,但這部份根據不同的ISA要有不同的設計。
- 有時候要放入nop(不做任何動作)
Dynamic是由CPU選擇每個cycle要issue哪些instructions,而compiler可以藉由把instruction串流做較好的排列來幫助。CPU會用比較進階的技術在運行時解決hazard。
Speculation:先去猜測要做什麼,如果做錯了再從頭來過。比如說branch的時候就先猜taken或not taken,在load的時候先拿原有的位址去load如果發現其他該在前面的instruction更新了這個位址,就roll-back。
Compiler可以重新排列一些code比如說把branch之前的load移到更早,避免stall,或是寫一些instruction來修正做出錯誤的speculation的狀況。增加用來延遲exception的ISA。
而硬體可以做look-ahead,將instruction的結果和exception都先存在buffer裡,直到他們要被用到或是判斷speculation正確。如果判斷speculation錯誤就把buffer flush掉。
dual issue
一個packet有兩組instruction。一個只做load/store一個只做ALU/branch,所以只要加一個ALU和一個sign extender就可以實做。
dual issue's Data hazard:
1 | add $t0, $s0, $s1 |
把這兩個指令拆開放在兩個不同的packets,就像stall一樣
Load-use hazard,一樣會造成一個cycle的延遲,但是一個cycle變成影響兩個instructions。
-> 需要把指令做更好的排程(aggressive scheduling)
loop unrolling: 把一次完成多個loop內的iteration來減少loop-control overhead(bne),並用不同的register來存放(register renaming)(每一份replicate就是原本的loop跑一次)
避免loop裡面有 anti–dependencies(name dependency): write-after-read
ex: B=7; A=B+1; B=3 在a=b+1和b=3之間就有anti dependent的關係

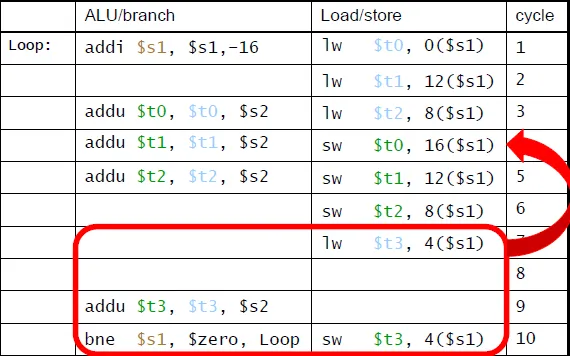
原本:for(load -> 計算 -> save)
之後:for(load) + for(add) -> for(save)
IPC從1.25提升到1.75(更接近極限,2)不過code和register也變得更大。
Dynamic multiple issue通常在超大型處理器中使用。CPU每個cycle會決定issue的對象。以幫助cpu對code的語義有更好的掌握(compiler做的事變少CPU更直接掌握code在做什麼)。
dynamic pipeline scheduling: 讓cpu可以不照順序執行instruction以避免stall,但是會把資料照順序存回register(比如說在stall的時候就先處理無關的instruction)
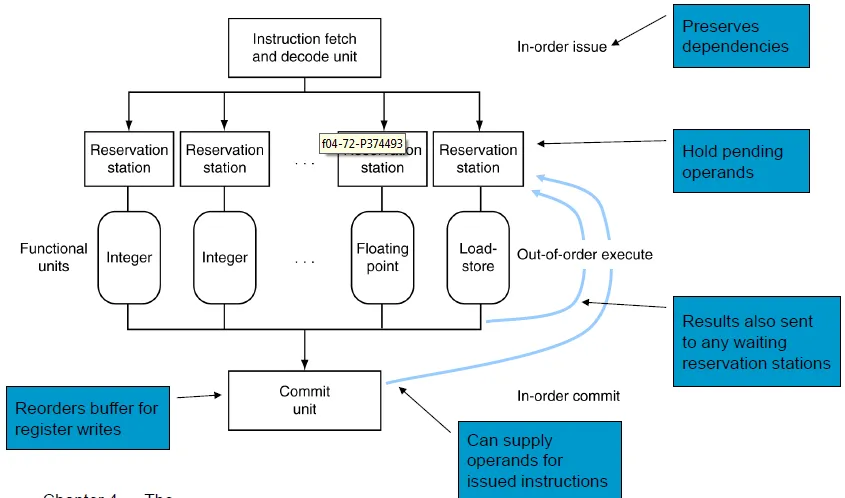
Dynamically scheduled CPU的運作跟一般的pipeline有些出入,可以分為4個stage
- IF/ID
照順序做完instruction fetch和decode(這邊的動作很快) - reservation stations
控制哪些instruction要先pending - functional units
做不同的功能 -- 浮點數運算, load-store...
完成後把資料給commit unit及相對應在pending等這個結果的reservation station - commit unit
重新排列register write要用的buffer
並提供operands給某些在reservation pending的function(類似之前單issue裡要flush重做的function)
?? Reservation station 和 commit unit在reorder buffer時,自動達到了register renaming。
?? 當一個instruction被issue到reservation station的時候,如果instruction的operands在register或reorder buffer裡可以被找到也可以被存取的話,把它複制到reservation station,並且標明那個register已經無用可以被複寫。如果operands無法存取(unavailable)的話,有一個function unit會把該給的值給reservation unit,而register裡面的值需不需要更新就要看指令。
dynamically scheduled的speculation: 在branching的結果確認之前不要commit。而speculation一樣可以用在減少load 和cache miss delay。根據預測的address先取出值然後等store有沒有更改到這個load的address,store會把那個address bypass到load unit。沒問題就把結果送到commit unit,有問題就重做。
Dynamically scheduling的原因:
不是所有的stall都是可以從code裡看出來的 比如說:cache miss。
branch的結果也不能靠scheduling來解決。
不同的ISA有不同的延遲和不同的hazard,都要交給compiler來處理實在非常麻煩。
Multiple issue的效能:程式內有dependency會限制ILP(instruction level parallelism)而且有些dependency很難去除,如pointer aliasing(不同的名字的pointer指到同一個地方)
有一些平行也很難做到比如說IF/ID的部份
memory還有delay而且也有他的頻寬,也導致pipeline常常有nop
Speculation如果做的好的話可以改善以上原因引起的performance下降
多顆簡單的核心(沒speculation, issue width低, pipeline, stage少)可以達到省電的作用
結論
pipeline的概念很簡單,但是細節很複雜。Ex: hazard detection
pipeline跟cpu的其他科技無關,其他科技進步的同時還是可以做pipelining
不好的ISA設計可能在某些狀況下會讓pipelining變得很困難
ex:
太複雜的instruction set 需要巨大的overhead來讓pipeline可行(ex: IA-32,VAX)
太複雜的addressing mode
間接讀取memory(指標),及register update
複雜的pipeline,會有比較長的branching delay slots
ISA會影響data path和control的設計
Pipelining利用平行處理的技術可以提高總輸出,並不影響單個指令的latency
Dependency限制了平行處理的程度,太過複雜又會導致電耗過高
Chap08 Memory Hierarchy
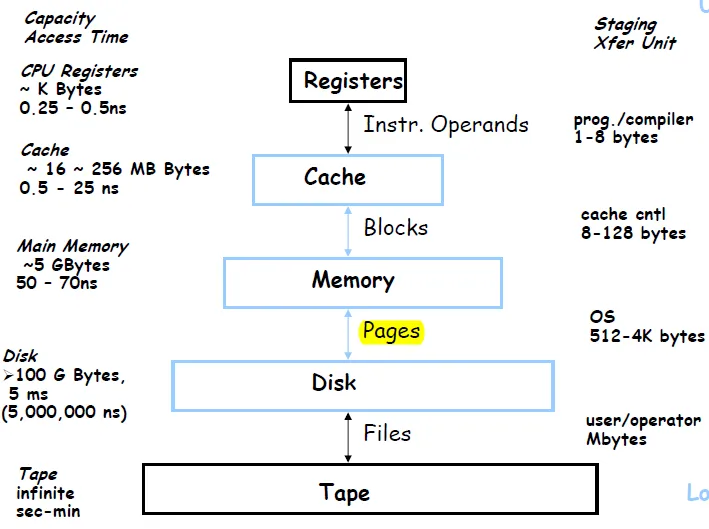
記憶體的層級化: 愈常用的放在愈快拿到的地方
- Static Ram: 0.5ns-2.5ns, 每gb要2000 – 5000元
- Dynamic Ram: 50ns -70ns 每gb要 20- 75元
- 硬碟:5-20ms,每gb只要0.2-2元
Temporal locality: 最近被存取過的data容易再被存取
Ex:在loop裡面的程序,或是在loop裡面一直被重複操作的數字
Spatial locality: 位址接近最近被存取過的data較有可能被存取,如array
資料的copy以block為最小單位。
Hit Time: memory access time + time to determine hit/miss
Miss Penalty: Time to replace a block in the upper level + Time to deliver the block to processor
direct mapped cache: mod餘1, mod餘2 … 各放在同一個cache block
memory address前面的bit也存過去做為tag,可知道是從memory的哪個位置將資料load到這個cache
Valid bit可以很快的判斷一個block裡面是否有資料
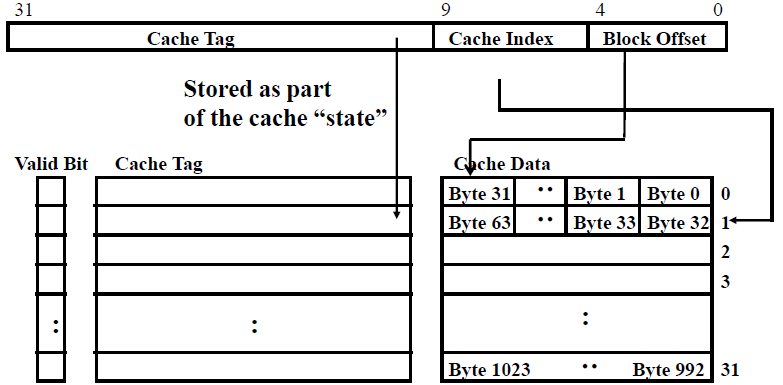
Q:How many total bits are required for a direct-mapped cache with 16 KB of data and 4-word(16byte) blocks, assuming 32bit address?
- num of sets = 16KB(cache size)/16B(block size) = 2^10
- num of data bits for each set = 16byte data = 4
- num of tag bits for each set = 32-10-4 = 18
Cache Controller FSM
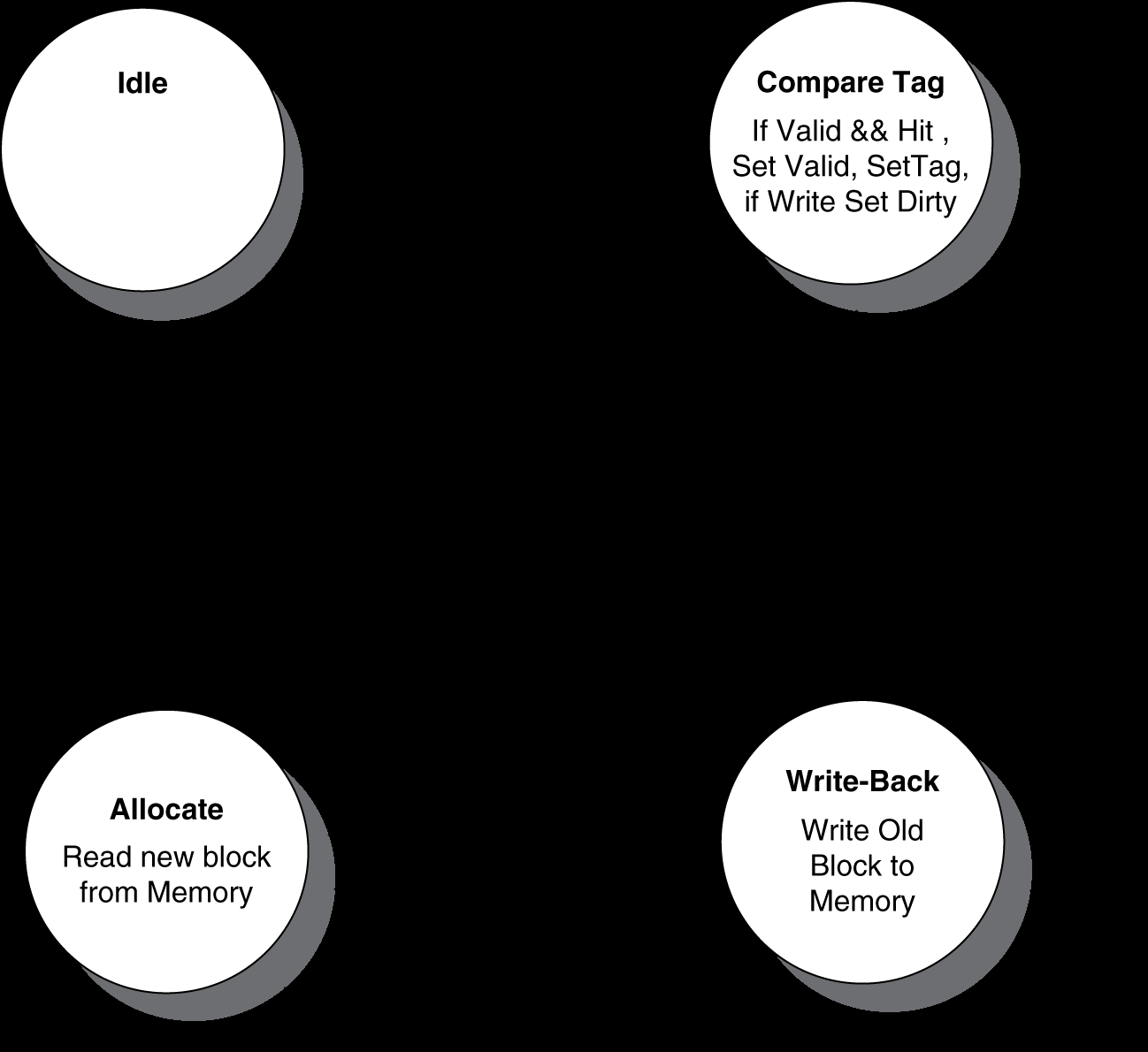
考慮因素
若增大block size,block數變少,有利於spatial locality,但miss penalty上升
解決miss penalty上升
- Early restart:正常運作,只要一fetch到需要的word,就馬上把這個word送到CPU
- Critical word first:先fetch需要的word,再把剩下的word填進cache bloc
各層級的資料不同步
- Write through:寫入cache時同時寫入memory
- Write back:cache被代替時,再寫入memory,設dirty bit
- 使用write buffer:只有在write buffer滿的時候才stall
Write Miss Policy
- Write allocate(fetch on write): 先load到cache再修改
- No Write allocate(write around): 直接write底層的資料,不load到cache
在做初始化時,寫入的資料(全都是0)不會在近期內就被讀取,採取write around就是一個比較好的選擇
是否合併instruction cache 和 data cache?
- Combined cache – higher cache hit rate & lower cache bandwidth
- Split cache – lower cache hit rate & higher cache bandwidth
memory interleave: 讓BUS可以同步讀取不同BANK
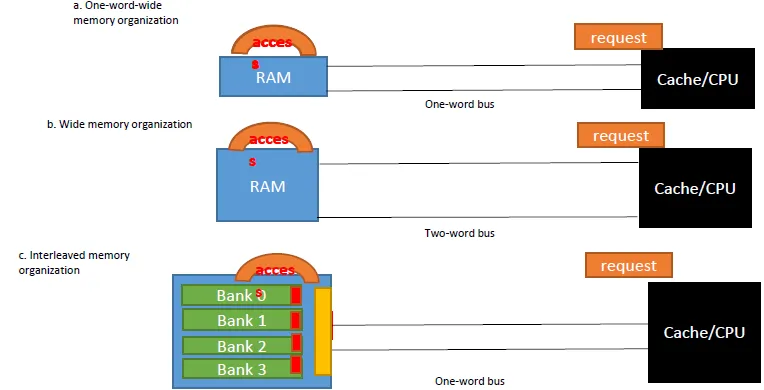
- DDR: RAM不只在clock 0變1時動作,在1變0的時候也做一次動作,使data rate變為兩倍故名 ddr
- QDR: DDR再加上將input 和output分開,在同一個clock變更時可以同時做input 和output的技術
當CPU的效能增進時,miss penalty的影響就越來越大
How to Improve Cache Performance?
- Reduce miss rate -> Increasing associativity
direct mapped -> set associative -> fully associative
效能提升呈邊際遞減
缺點:mux delay, data comes after hit/miss, tag bit increase - Reduce miss penalty -> multi-level cache
high performance improvement
Ex. radix sort: cache miss rate high, so performance worse than quick sort - Reduce hit time -> small cache(...)
記憶體的層級化(memory hierarchy):每一層裡面都有4個重點,block要怎麼放置,要怎麼找到需要的block,當miss的時候怎麼替換,寫入時的規矩(write policy)。
- block要怎麼放置:由associativity決定。可分為direct mapped, n-way,和fully associative。越高的associatvie就越少miss但是cost,access time 和複雜度也越高。(三種associative參考前面)
- 要怎麼找到需要的block: direct mapping需要做1次的comparison,n-way需要做n(看多少way)次,而fully associative如果建表就不用沒的話就要做entry的次數次(每個entry都要比對)。這邊我們的目標是降低comparison以降低硬體cost。VM由於full look-up table的查表方式使得fully associative可行,可以大大降低miss rate。
- 當miss的時候怎麼替換(algo): 替換的方法有LRU和random兩者比較在前面講過了。在VM裡面的話我們藉由硬體的幫忙實作LRU。
- Write policy:write-through和write-back,在VM裡只有write-back可行(28點)。
Chap 08-2 Virutual Memory
Idea: use memory as cache for disk
block叫做page,miss叫做page fault
Disk讀取的速度非常慢,要花上百萬個cycle。必須使用Fully associative和較佳的replacement algorithm,及軟體為主的exception handler
page fault 發生時,os會把相對應的page抓進來並update page table然後再重新執行導致page fault的instruction
LRU replacement: 每個PTE(entry)加個bit叫reference bit,每次當這個page 被access就把這個reference bit設為1,然後系統會自動定期將所有 reference bit 清為0,這樣我們可以判斷reference bit是0的page最近沒有被access。
-
Page table:由virtual page number作index,值為physical index。
-
Page table can be very large!
–Solution: inverted page table & multi-level paging -
inverted page table: use hash to search(非常耗時、無法支援Memory sharing)
-
multi-level: 分層, decrease total page table size
![two-level]()
-
TLB(translation look-aside buffer)可以很快的cache在cpu內存放PTE。通常可存放16~512個PTE,hit時只要花0.5~1個cycle,miss的話也只要10~100個cycle。並且有0.01%~1%的低的miss rate
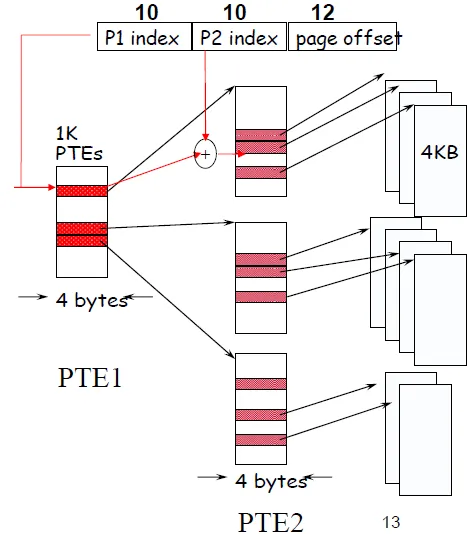
不同的任務(task)有時候可以共用他們的虛擬位址,但是需要OS的協調指派,並防止不相干的程式的access。
需要硬體的支援: kernel mode, 包含特有的instruction. page table和他的state資訊只有在kernel mode下可以access。並且還要有system call exception
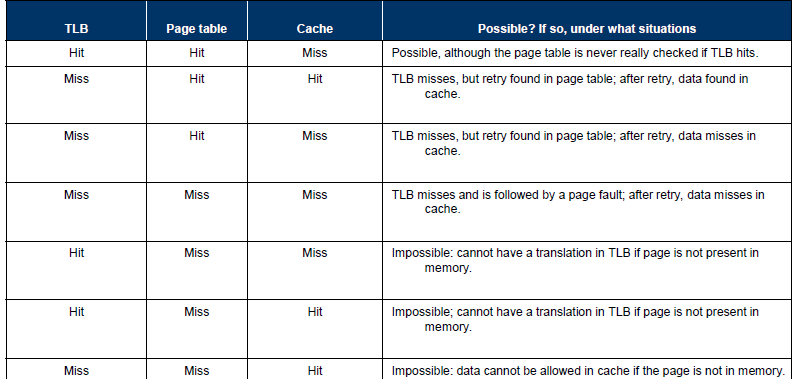
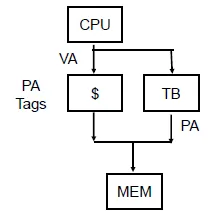
Virtually Addressed Cache only Translated on miss
distinguish data of different processes
-> Virtually indexed & physically tagged cache
-> read data by tag and translate index in the same time
Performance issue in Virtual Memory
Thrashing Solutions: Buy more memory
High TLB misses Solutions:Variable page size
- compulsory misses,也叫做cold-start misses。資料第一次被存取。
- capacity misses,cache的大小有限,一個剛被replace掉的block馬上又需要被access。
- conflict misses(collision misses)。多個block要競爭同一個index的entry,如果是fully-associative就不會發生
![3C absoluate miss rate]()
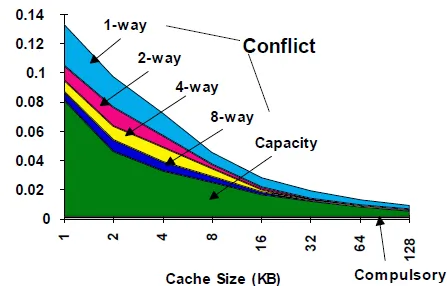
若想要減低miss rate, 就會造成總體效能的負面效應。
Trends:
–Redesign DRAM chips to provide higher bandwidth or processing
–Use prefetching & non-blocking cache (make cache visible to ISA)
–Restructure code to increase locality
Reduce miss penalty
- Non-blocking caches
- Non-blocking cache or lockup-free cache allowing the data cache to continue to supply cache hits during a miss
- Prefetching
- Requesting data early, so it’s in cache when needed.
- 預測技術(complier or hardware)
- Problem: May replace data in cache that is still needed.
VMM(virtual machine monitor)將虛擬的資源map到實體資源上,ex: memory I/O, CPU。guest的code在我們的本機端跑時是使用user mode,VMM可以控管一些要有權限才能用的instructions和一些資源是否可以access。Guest的os可能跟我們使用不同套,於是vmm就要產生一個虛擬的I/O給guest使用,來處理真正的I/O。
如果VM request一個timer-interrupt,這時候vmm就會根據本機的timer虛擬出一個虛擬的timer。利用這個timer來判斷interrupt的發生。
在vm上所有必須access實體資源的動作都要透過由VMM監控的privileged instructions才使用。比如說page tables, I/O , interrupt controls, registers等。
做某一些動作比如說要建立多重的web service時,所有東西都要經過VMM,VMM就回成為一個很大的 threshold。
Chap 10 Storage, Network and Other Peripherals
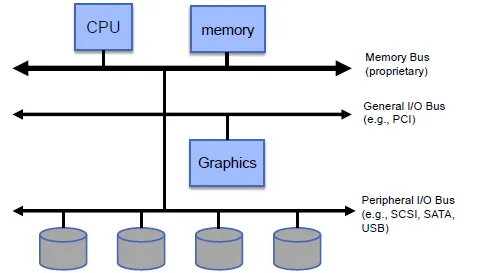
I/O Device Characteristics
- behavior
- input, output or storage
- partner
- data transmit rate
performance metrics: Throughput, Response time
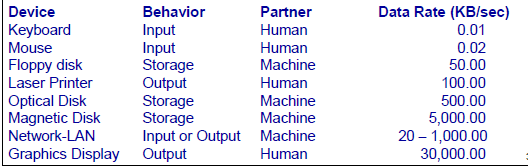
I/O System performance: find limited by weakest link in the chain
: CPU, memory, bus, IO controller, IO device, OS, software
Two common
reliability
- MTTF:平均要多久會出現一次failure
- MTTR:平均遇到failure以後多久會修好
- availability是MTTF/(MTTF+MTTR)
- 改進availability
- 增進MTTF,有避免fault的發生,減少fault發生時造成的損失,還有fault的預測
- 減少MTTR,加強repair,增強fault的原因的分析功能,還有repair的機制
Disk Performance
seek time: 上下移動
Rotational latency: 轉到讀取的資料所需時間(RPM),平均計算:轉一半(0.5round)
transfer rate: 傳送資料速度
Controller time: I/O controller花的時間
快閃記憶體(flash)比硬碟快上100~1000倍。
比較小,比較不耗電。但是比較貴(介於disk和dram之間。)
Flash可以分為NOR或NAND flash。
NOR flash是random access通常用在嵌入式系統的instruction memory。
NAND 同時只能access某個block,而且同樣的大小有比較大的容量。成本也比較低。通常用來當我們常用的usb drive或記憶卡,SSD等等。
Flash的bit約在access 千次以後會壞掉。所以不適合拿來做ram或硬碟。解決方法是把data平均放在每個block上。
flash's block: 包含多個page
- Write Once: 無法直接覆蓋檔案,需先清除,一次清除一個block
- When # of free pages <= Garbage Collection Threshold
: move live page to other block , and erase this block
SSD (Solid Storage Disk)
no actual "disk", use integrated circuit assemblies as memory to store data persistently.
SSD uses electronic interfaces compatible with traditional block drives
- no mechanical failure
- Green
- SSDs consume over 50% less power compared to HDD
- Higher initial cost
- Ex. Facebook data center
- Active SSD: 在I/O端作(簡單的)計算,減少L/W時間
將PCI-e flash作為I/O cache(比SSD快!)放在General IO bus 上以加速I/O
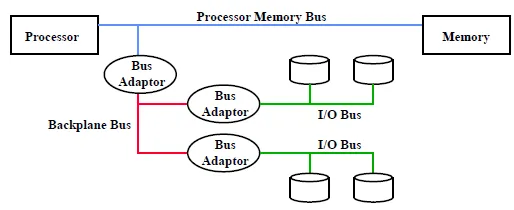
Bus: Connection between Processors, Memory, and I/O Device
有很好的同步性和低維護費,但造成效能瓶頸(受限於長度,BUS數目…)
有Control line 和 Data line
Bus可以分為
- Processor-memory bus: 較短較快,要照著memory的規劃做設計
- I/O bus: 較長,可以有多重的互相連結。要照著互通性的基準設計
- Backplane bus: 所有device都可連接,花費較少,用來連接前兩者
Synchronous Bus:
- includes a clock in the control lines
- advantage: involves very little logic and can run very fast
- disadvantages:
- every device on the bus must run at the same clock rate
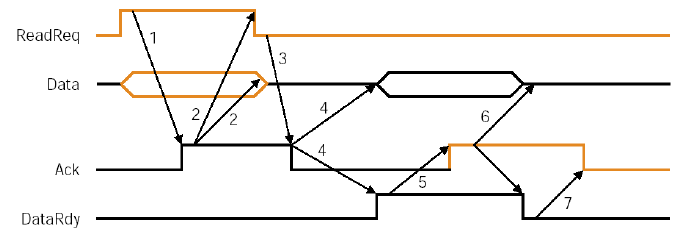
Asynchronous Bus:
- No clock, can accommodate a wide range of devices
- can be lengthened without worrying about clock
- requires a handshaking protocol
![Asynchronous handshaking: Read Transaction]()
Multiple Potential Bus Masters: use Arbiter to control
Arbiter: select who can use bus by priority and fairness
Daisy Chain Bus Arbitrations
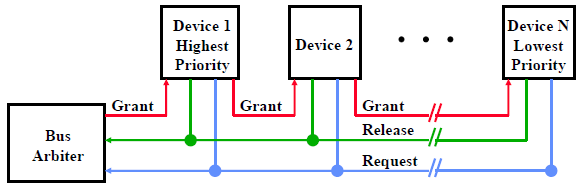
Advantage: simple
Disadvantages:
–Cannot assure fairness: A low-priority device may be locked out indefinitely
–The use of the daisy chain grant signal also limits the bus
speed
Centralized Parallel Arbitration
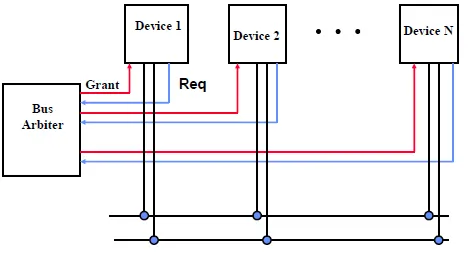
所有bus由arbiter控管
適合速度較快的device組成的bus
I/O的設備是由I/O controller來管理並同步。
command register來存放不同的command 使用不同的command來讓I/O device執行不同的動作
status register來指出I/O設備現在正在執行什麼task還有是否遇到什麼error
data register,可以把data “write”到device或從device ”read”出data。
Memory mapped I/O
I/O的register的位址設為跟memory中的位址一樣,只有在kernel mode時可以access這些address
Communicating with the Processor
‧Polling
定期檢查I/O status register,如果是ready就執行I/O,如果是error就想辦法解決。叫polling(問卷調查)。會浪費太多cpu time(busy loop)。
有反應時間需求時使用
‧Interrupt
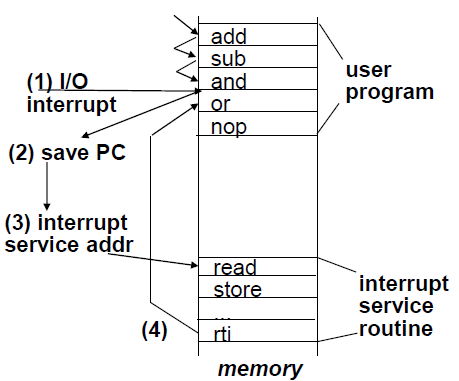
當ready或error時,controller就會interrupt CPU。
Interrupt跟exception很像,但可以在兩個instruction之間觸發handler。通常可以由cause的資訊來分辨是哪個device發生interrupt。Interrupt也有不同的priority,越緊急的interrupt priority就會越高。也可以用高priority的interrupt來呼叫低priority的interrupt的handler。
high-speed devices are associated with higher priority
‧DMA(direct memory access)
I/O controller主動跟memory連結傳輸資料,直到傳輸完成或是error才interrupt。比較節省cpu-time。
DMA寫到memory後,可能造成memory和cache不一致
如果write-back cache有dirty block而DMA去讀到相對應的memory的話也會讀到錯誤的資料。解法:cache的內容如果在memory中被dma寫入就把那個cache flush掉,不然就要設定noncacheable(dma不能動在cache的資料)。
Parallelisms and I/O
RAID: Redundant Array of (inexpensive)Independent Disks。
使用很多個小的disk來取代一個大的disk,好處有資料較不易受損和平行處理速度加快
‧Improve availability with redundancy
Raid 0,是最早的RAID,沒有redundancy,只是把資料分散在不同的小disk可以平行讀取
RAID 1(Disk Mirroring):是兩個一模一樣的disk,一個是當作備份用,如果主disk的資料受損就從mirror copy過去
RAID 2: 把資料拆到以bit為單位分散的存在disk內。並用E-bit來做Error correction。拆到以bit為單位的話假設有n個disk則要讀任何資料理論上可以有n倍快。但是太複雜的設計導致實際上raid2並沒有在使用。只用於memory
Raid3(Bit-Interleaved Parity):
使用N+1個disk,資料拆成bit level分散在n個disk上
用剩下來的disk存parity(前面n個disk裡相對應的位址的每個資料做XOR)
在read時就讀取所有的disk,在write時寫入每個disk並產生新的parity。遇到failure時根據parity可以判斷failure的bit。
RAID4:
跟raid3很像只是是拆成block level,每次要讀資料時只要讀存放所需資料的block就好,寫資料也只需要動到要寫的block和parity。
RAID5:
跟RAID4接近,但是把parity分散存至每個disk以避免parity disk成為在寫入時的速度的瓶頸(Raid4每個寫入都要寫parity disk,所以parity disk寫入的速度就會限制資料寫入的速度)
RAID6(P + Q Redundancy):
跟RAID5一樣但是增加兩個parity(不同演算法),使系統容錯率更高。
RAID summary:
raid可以提升performance 並增加可靠性(hot swapping,在不影響系統operate的情形下修復fault)
可靠性是raid最重要的功能。
Disk I/O Benchmarks: I/O rate vs. Data rate vs. latency
Chap12 Multicores, Multiprocessor
Challenges
- Partitioning
- Coordination
- Communication overheads
- Amdahl’s Law
平行化是有極限的
FracX: 能被speedup的比例
Speedup = 1 / [(FracX/SpeedupX + (1-FracX)]
資料傳遞
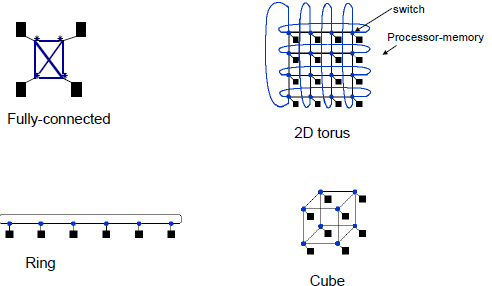
Shared Memory: connect by memory
use lock to synchronize
same address space
Message Passing: connect by network
different address spaces
Total network bandwidth = 所有的頻寬。bandwidth-per-link x link_no
Bisection bandwidth = 兩個部分之間的頻寬。the bandwidth between two parts of a multiprocessor
Cache Coherency Problem: 在cache中的共享資料須保持一致
Protocol:
- Snoopy Bus: use for small scale machines
在拿資料前,先boardcast給所有processor知道
allow multiple readers, single writer
Broadcast: BW (increased) vs. latency (decreased) tradeoff
Write Invalidate Protocol:
若寫資料,也boardcast,其他有同資料的processor設invalid bit
Write Update Protocol:
若寫資料,也boardcast,其他有同資料的processor作相同的instruction
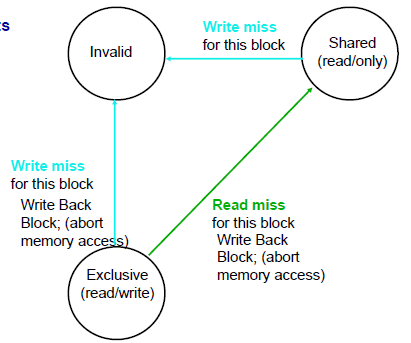
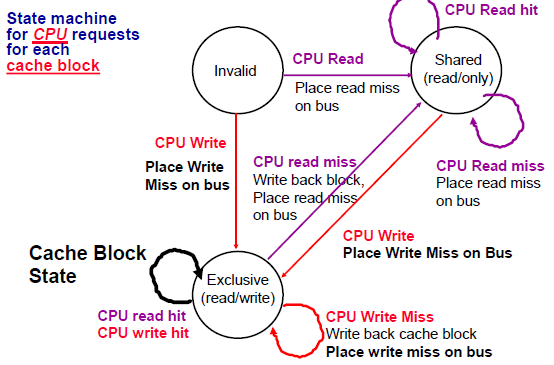
Each block of memory is in one state:
–Clean in all caches and up-to-date in memory
–OR Dirty in exactly one cache
–OR Not in any caches
Each cache block is in one state:
if read miss, place readmiss on bus, goto shared
if write miss, place writemiss on bus, goto exclusive
if get read miss at bus(same block), if at exclusive, do write back and goto shared
if get write miss at bus, goto(set) invalid
–Shared: block can be read
–OR Exclusive: cache has only copy, its writeable, and dirty
–OR Invalid: block contains no data
- Basic CMP Architecture Shared last level cache
- Scalable CMP Architecture Tiled CMP
- Each tile includes processor, L1, L2, and router
- Physically distributed last level cache
Multithreading
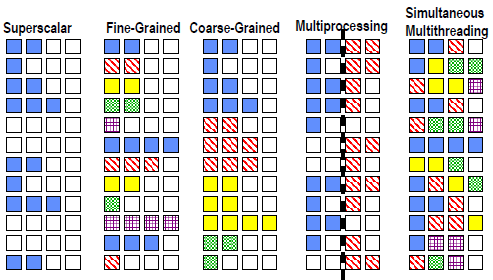
- 實作多執行緒
- 有多個 registers, PC
- Fast switching between threads
- 減少stall的時間浪費
- Fine-grain multithreading(一個cycle做一個thread的多個cycles)
- Coarse-grain multithreading(只有大的stall(L2 cache miss)才切換thread)
- Simultaneous Multithreading
- used in dynamically scheduled processor
- 同一個cycle可做多個thread
- dependencies handled by scheduling and register renaming
- 和Multiprocessing的不同:multiprocessing需多個processor
費林分類法(Flynn's Taxonomy),是一種高效能計算機的分類方式
- 單一指令流單一資料流計算機(SISD)
- 單一指令流多資料流計算機(SIMD)
- processors execute the same instruction at the same time.Each with different data address
- Works best for highly data-parallel applications
- Vector architecture
- Explicit statement of absence of loop-carried dependences(Reduced checking in hardware)
- Avoid control hazards by avoiding loops
- 多指令流單一資料流計算機(MISD)
- 多指令流多資料流計算機(MIMD)
- SPMD: Single Program Multiple Data
- A parallel program on a MIMD computer
- Conditional code for different processors
GPU(Graphics Processing Units)
- compute massive vertices, pixels, and general purpose data
- High availability
- High computing performance
- Low price of computing capability
General-Purpose computing on GPU (GPGPU)
用處理圖形任務的圖形處理器來計算原本由中央處理器處理的通用計算任務,這些通用計算常常與圖形處理沒有任何關係。由於現代圖形處理器強大的並行處理能力和可程式流水線,令流處理器可以處理非圖形數據。特別在面對單指令流多數據流(SIMD),且數據處理的運算量遠大於數據調度和傳輸的需要時,通用圖形處理器在性能上大大超越了傳統的中央處理器應用程式。
GPGPU programming models
- NVIDIA’s CUDA
- AMD’s StreamSDK
- OpenCL
Multi-core CPU
- Coarse-grain, heavyweight threads
- Memory latency is resolved though large on-chip caches & out-of-order execution
Modern GPU - Fine-grain, lightweight threads
- Exploit thread-level parallelism for hiding latency
- SIMT (Single Instruction Multiple Threads)
- multiple independent threads(pixel, vertex, compute…) execute concurrently using a single instruction
- common PC value
- Latency Hiding
Serial/Task-parallel workloads → CPU
Graphics/Data-parallel workloads → GPU
Behaviors of the applications are different
-> CPU is latency sensitive, GPU is throughput oriented
參考資料
- CA_by_b95015.doc