MapReduce 簡介
Metadata
| Title | MapReduce: Simplified Data Processing on Large Clusters |
| Conference Proceedings Title | OSDI '04 |
| Authors | Jeffrey Dean, Sanjay GhemawatCheng |
| Date | 2004/10 |
| Page | 13 |
| Times cited | 34516 |
Introduction
- Motivation: Lots of special-purpose programs should process large amounts of raw data
- e.g., crawl(analyze) documents, web request logs, etc.
- Inspiration
Map()andReduce()primitives present in Lisp and many other functional languages
- Solution: Design a programming model:
MapReduce- Hides the details of parallelization, fault-tolerance, locality optimization, and load balancing
Map and Reduce
- Divide, Conquer, and Combine → Divide, Map, and Reduce
- User only need to implement
Map()andReduce()functions and tune settings- MapReduce model already implement other things to do
Programming Model
Map()- Produce a set of intermediate key/value pairs
- After
Map()complete- Sort intermediate key-value pairs and divide into pieces for
Reduce()to use
- Sort intermediate key-value pairs and divide into pieces for
Reduce()- Merge the value of the same intermediate key
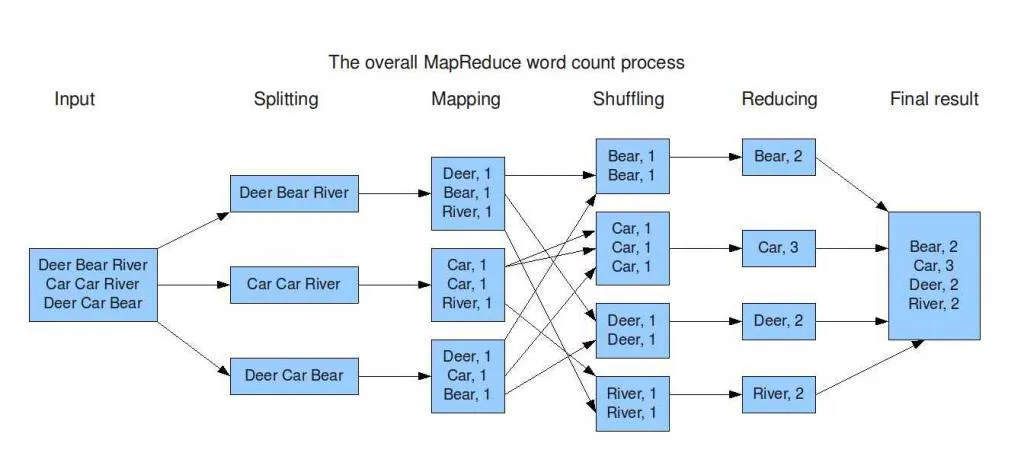
Example
Input → After Map → After Reduce
- Search (in a large file set)
- Inverted Index
<doc, docID>→<word, docID>→<word, list(docID)>
- Reverse WebLink
sourceURL→<sourceURL, targetURL>→<targetURL, list(sourceURL)>
- Inverted Index
- Count (in a large file set)
- URL Frequency in webpage
URL→<URL, 1>→<URL, TotalCount>
- Term Frequency
term→<term, freq>→<term, freq>![]()
- URL Frequency in webpage
- Sort (in a large file set)
unsorted list→seperated sorted list→merged sorted list
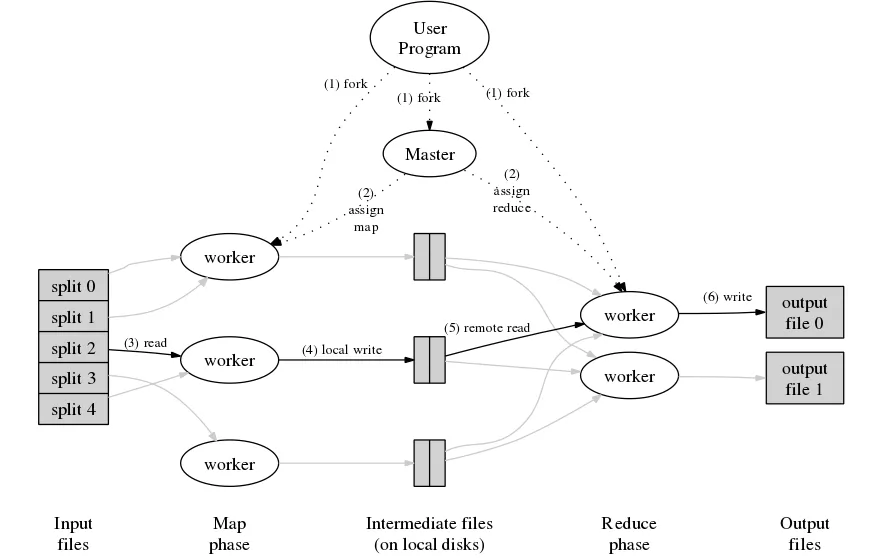
Implementation
Use C++ to implement
- Data storage
- 資料存放在GFS(Global File System), 64MB為一個BLOCK
- 存放多個複本於不同機器
- 網路頻寬是稀缺資源
- Worker和資料若在不同機器,會傳輸很久
- Master儘量分配Worker使用本地有資料的任務
- Worker和資料若在不同機器,會傳輸很久
- 資料存放在GFS(Global File System), 64MB為一個BLOCK
- Task assign
- 將
Map()分成 $M$ 個任務, 將Reduce()分成 $R$ 個任務- $M$ 和 $R$ 的數量比可用的機器多很多
- Master 需要分配 $O(M+R)$ 個任務 和 記錄 $O(M \times R)$ 塊資料
- 切得愈小,故障代價愈小,較容易平均分配,但Master需要記較多資料
- 一塊通常是16~64MB,以配合GFS
- Google的設定:$M$ = 200000, $R$ = 5000, using 2000 worker machines
- 將
- Input
- Input of Map: 把 Input data 切成 $M$ 塊
- Input of Reduce: 把 Intermidiate data 切成 $R$ 塊
- Intermediate key and set of values of the key
- 用 hash(key) mod R 的值來代表 key 是第幾塊
- Master program: 分配任務
- Map worker
- 執行完後將 $R$ 塊Intermediate資料寫入本地磁碟
- 回傳檔案位置至Master
- Reduce worker
- 從Master得知檔案位置,使用Remote Procedure Call(RPC)來讀取資料
- Map worker
故障容忍 Fault Tolerance
- Worker故障
- 可能是網路、硬碟、機器故障
- Master定期ping worker
- 若沒有回應,視為死掉
- 原先分配給死掉的Task會重新分配
- 已完成的Reduce任務不需要重新分配
- 資料已存放在全域資料系統(Map的結果資料放在本地端)
- 通知Reduce Worker新的資料路徑
- Master故障
- 幾乎不會發生(因為只有一台)
- 定時記錄進度,以便還原
Backup Tasks
- Straggler(落後者): 完成Task的時間很長
- 可能原因
- 磁碟故障
- 記憶體不足
- 網路不穩
- 程式的bug
- 在做其他任務
- 可能原因
- 解法: 若MapReduce快完成時, Master 對還在執行的Task,執行多份備份Task
- 只要其中一個完成即可
- 只多消耗一點運算資源,可減少30%耗時
Performance
- Environment
- 1800 machines
- two 2GHz Intel Xeon processors with Hyper-Threading enabled
- 4GB of memory
- two 160GB IDE disks
- 1 gigabit Ethernet link
- 1800 machines
- 測試兩種Task
- Grep 1TB data
- Sort 1TB data
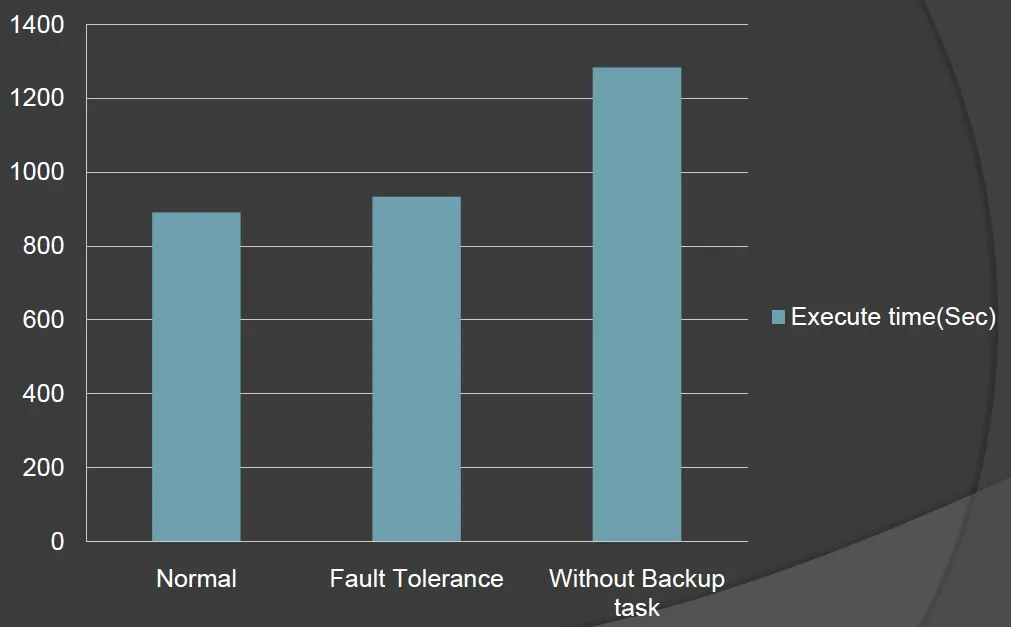
- Performance
- Normal Execution
- 891sec
- 刻意殺掉200個worker(總共1746個)
- 933sec
- only 5% increase
- 沒有Backup Task的情況
- 1283sec
- 44% increase
- Normal Execution
Refinement
- Locality Optimization
- 將輸入檔案複製到本地磁碟
- Ordering Guarantee
- 保證 Intermediate key/value 已排序
Reduce()處理時速度較快
- Combiner Function
- 考慮計算次數的任務,會送出很多
<key,1>的records,可在Map()之後先做簡易的Reduce(),稱為Combine- 可減少網路傳輸量
- 考慮計算次數的任務,會送出很多
- Partitioning Function
- 預設使用Hash Function 來分割成 $R$ 個檔案
Hash(key) mod R
- 特殊情況可以用別的,如key為網址的時候希望相同Host的資料放在同一個
Reduce()Task上Hash(Hostname(url)) mod R
- 預設使用Hash Function 來分割成 $R$ 個檔案
- 輸入和輸出
- 使用介面來實作新的輸入/輸出類別
- 輸入類別
- 文字處理類別 (Text Mode)
- 每一行都是 key/value pair
- Key: 此行的檔案 offset
- Value: 此行的內容
- 每一行都是 key/value pair
- key/value pairs 的類別
- 用來保持key的排序
- 文字處理類別 (Text Mode)
- Side Effects
- e.g., 執行
Map()或Reduce()時,產生附加檔案(Auxiliary Files) - Make sure side-effect is atomic and idempotent(冪等)
- Idempotent:一個運算作用在任一元素兩次後會和其作用一次的結果相同
- e.g., 執行
- Skipping Bad Records
- 忽略少數的故障(當資料夠大時)
- 對答案影響不大
- 故障時,傳送資料給Master
- 連續錯N次後,直接跳過此輸入
- 忽略少數的故障(當資料夠大時)
- 實作Counter類別
- 在
Map()和Reduce()計算數量用 - 定期傳送資料給Master以追蹤進度
- 在
- Local Execution
- 將全部資料於同一台電腦中執行(即單機版本),以利Debug
- Status Information
- Master有http server提供狀態頁面,以提供進度監控
結論
- 此框架隱藏了錯誤處理、平行化、分散式系統、資源分配的細節
- 沒有分散式系統和平行化的經驗也可以輕鬆上手
- 只需思考分割和組合資料的邏輯
- 程式邏輯更簡單,更容易修改
- 3800行 → 700行 (C++)
- 沒有分散式系統和平行化的經驗也可以輕鬆上手
- 適合用來處理可以分割、資料量大的問題
應用
因為是非常一般化的框架,可用在許多用途
- 資料處理
- 統計,如PageRank
- 搜尋,如Google Search Indexing
- 排序
- 機器學習
備註
Map()和Reduce()的實作必須是Deterministic- 否則因為機器故障、輸入順序不同等因素,輸出可能會不同
- Hadoop 為 MapReduce 的 Open Source 實作
參考資料
- Jeffrey Dean and Sanjay Ghemawat, 2004, MapReduce: Simplified Data Processing on Large Clusters
- 簡報