自然語言處理(下)
Chap08 Syntax and Grammars
Grammar
- represent certain knowledges of what we know about a language
- General criteria
- linguistic naturalness
- mathematical power
- computational effectiveness
Context-free grammars(CFG)
- Alias
- Phrase structure grammars
- Backus-Naur form
- More powerful than finite state machine
- Rules
- Terminals
- words
- Non-terminals
- Noun phrase, Verb phrase ...
- Generate strings in the language
- Reject strings not in the language
- LHS → RHS
- LHS: Non-terminals
- RHS: Non-terminals or Terminals
- Context Free
- probability of a subtree does not depend on words not dominated by the subtree(subtree出現的機率和上下文無關)
- Terminals
Evaluation
- Does it undergenerate?
- rules cannot completely explain language
- not a problem if the goal is to produce a language
- Does it overgenerate?
- rules overly explain the language
- not a problem if the goal is to recognize or understand well-formed(correct) language
- Does it assign appropriate structures to the strings that it generates?
Parsing
- take a string and a grammar
- assigning trees that covers all and only words in input strings
- return parse tree for that string
English Grammar Fragment
- Sentences
- Noun Phrases
- Ex. NP → det Nominal
- head: central criticial noun in NP
- important in statistical parsing
- after det(冠詞), before pp(介系詞片語)
![]()
- Agreement
- a part of overgenerate
- This flight(○)
- This flights(×)
- Verb Phrases
- head verb with arguments
- Subcategorization(分類)
- categorize according to VP rules
- a part of overgenerate
- Prefer
- I prefer [to leave earlier]TO-VP
- Told
- I was told [United has a flight]S
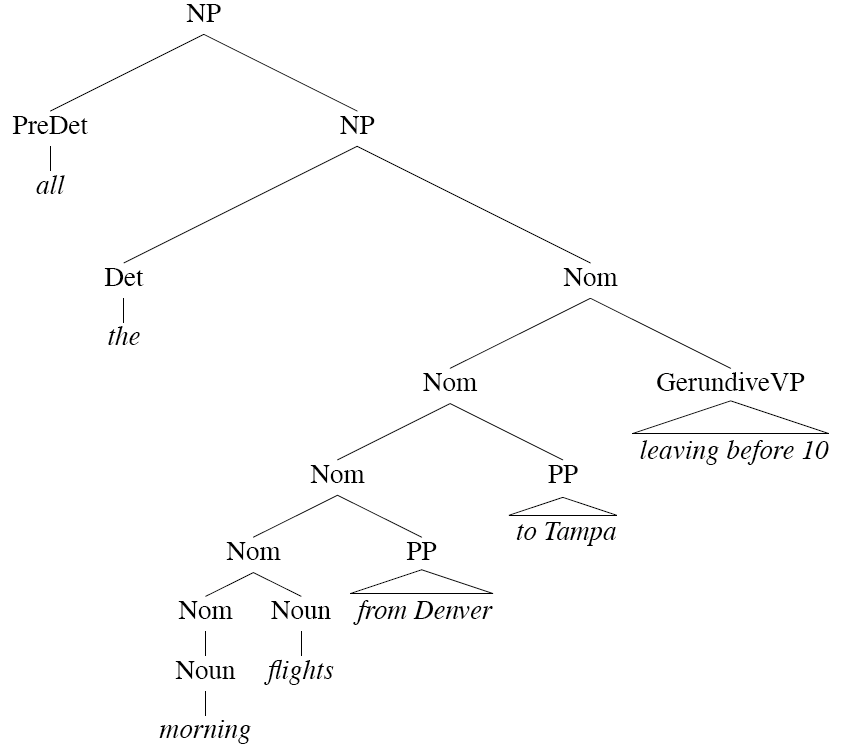
Overgenerate Solution
- transform into multiple rules
- NP → Single_Det Single_Nominal
- NP → 複數_Det 複數_Nominal
- Will generate a lot of rules!
- out of CFG framework
- Chomsky hierarchy of languages 
Indexed Grammar
- Indexed grammars and languages problem
![]()
- recognized by nested stack automata
![]()


Treebanks and headfinding
critical to the development of statistical parsers
Treebanks
- corpora with parse trees
- created by automatic parser and human annotators
- Ex. Penn Treebank
- Grammar
- Treebanks implicitly define a grammar
- Simply make all subtrees fit the rules
- parse tree tend to be very flat to avoid recursion
- Penn Treebank has ~4500 different rules for VPs
- Treebanks implicitly define a grammar
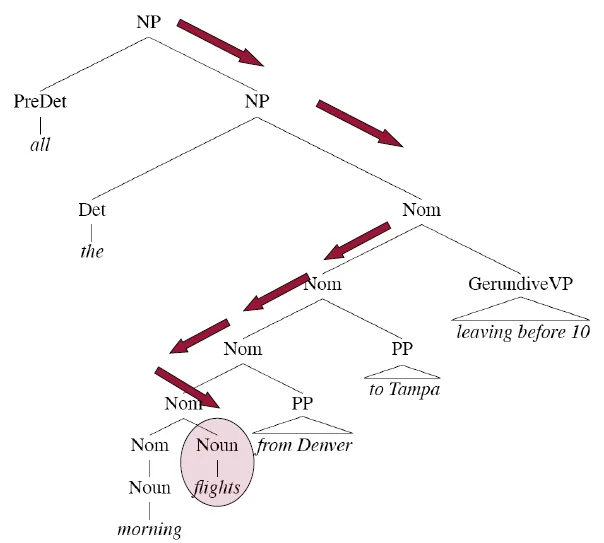
Head Finding
- use tree traversal rules specific to each non-terminal in the grammar
- 先向右再向左
![]()
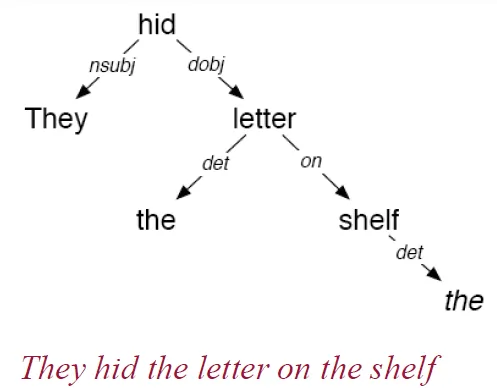
Dependency Grammars
- every possible parse is a tree
![]()
- every node is a word
- every link is dependency relations between words
- Advantage
- Deals well with long-distance word order languages
- structure is flexible
- Parsing is much faster than CFG
- Tree can be used by later applications
- Deals well with long-distance word order languages
- Approaches
- Optimization-based approaches
- search for the tree that matches some criteria the best
- spanning tree algorithms
- Shift-reduce approaches
- greedily take actions based on the current word and state
- Optimization-based approaches
Summary
- Constituency(顧客, words that behave as a single unit) is a key phenomena easily captured with CFG rules
- But agreement and subcategorization make problems
Chap09 Syntactic Parsing
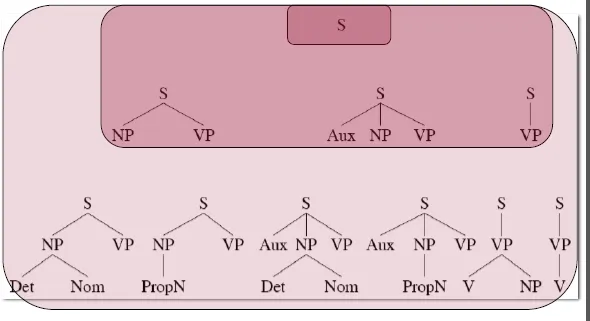
- Top-Down Search
![]()
- Search trees among possible answers
- Bottom-Up Parsing
- Only forms trees that can fit the words
- Mixed parsing strategy
- looks like Binomial Search
- The number of rules tried at each deicision of the analysis (branching factor)
- top-down parsing: categories of LHS(Left Hand Side) word
- bottom-up parsing: categories of left most RHS(Right Hand Side) word
- 倒推:從最左邊可以倒推的字開始
backtracking methods are doomed because of two inter-related problems
- (1)Structural and lexical ambiguity
- PP(介系詞片語) attachment
- PP can attach to [sentences, verb phrases, noun phrases, and adjectival phrases]
- coordination
- P and Q or R
- P and (Q or R)
- (P and Q) or R
- P and Q or R
- noun-noun compounding
- town widget hammer
- ((town widget) hammer)
- (town (widget hammer))
- town widget hammer
- Solution
- how to determine the intended structure?
- how to store the partial structures?
- PP(介系詞片語) attachment
- (2)Shared subproblems
- naïve backtracking will lead to duplicated work(不一定會對,所以會一直backtrack...)
Dynamic Programming
- Avoid doing repeated work
- Solve in polynomial time
- approaches
- CKY
- Earley
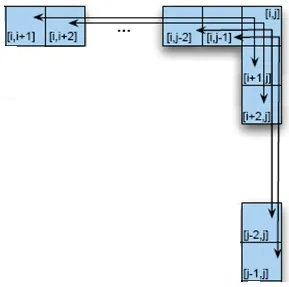
CKY(bottom-up)
- transform rules into Chomsky-Normal Form
![]()
- build a table
- A spanning from i to j in the input is in [i,j]
- A → BC == [i,j] → [i,k] [k,j]
- entire string = [0, n]
- expected to be S
- iterate all possible k
![]()
- [i,j] = [i,i+1]x[i+1, j], [i,i+2]x[i+2,j] ......
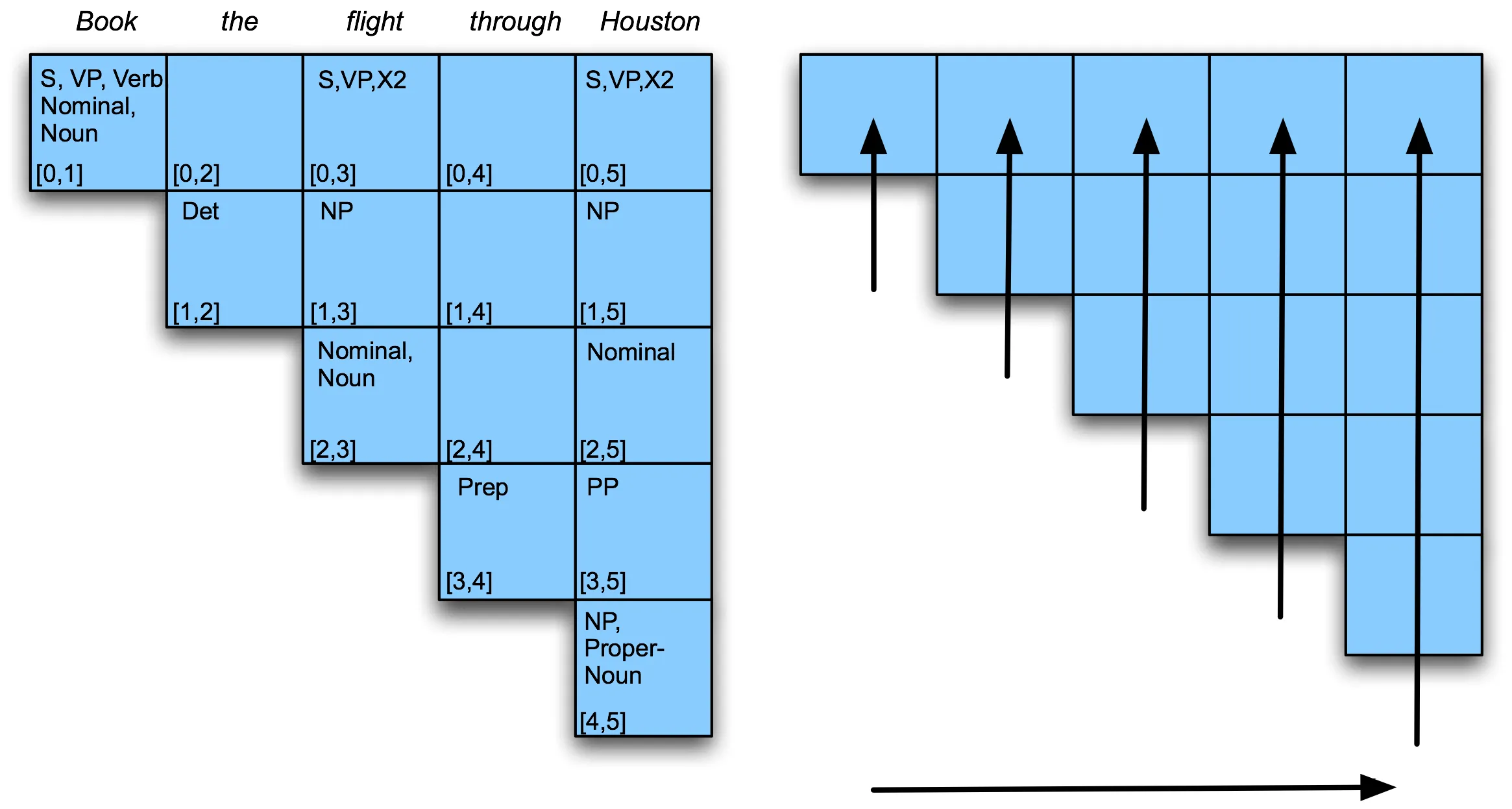
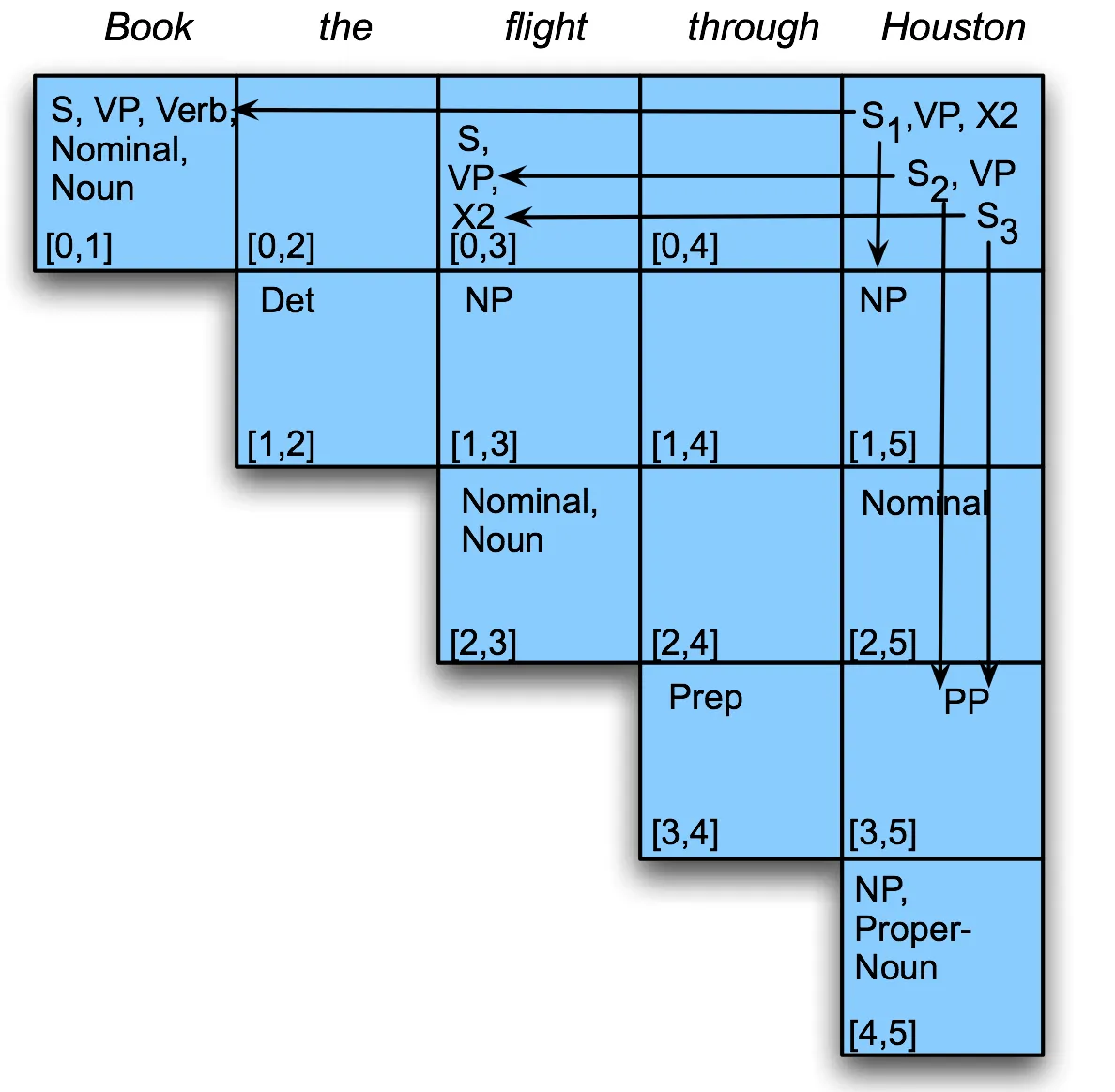
- fill the table a column at a time, from left to right, bottom to top
![]()
- Ex. [1,3] = [1,2]Det + [2,3] Nomimal, Noun = NP
- Ex.
![]()
- Algorithm
![]()
- Performance
- a lot of elements unrelated to the answer
- can use online search to fill table (from left to right)
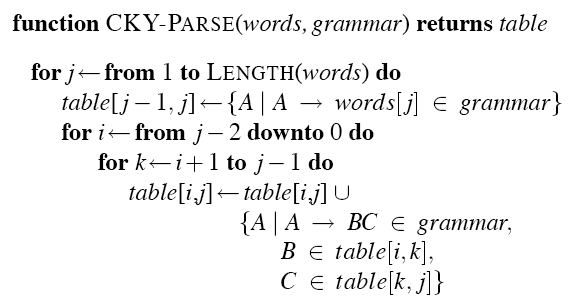
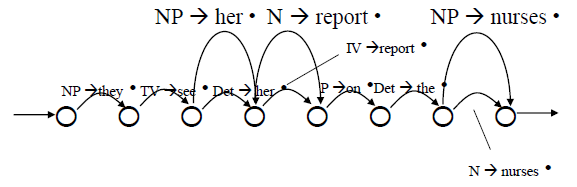
Earley
- parser that exploits chart as data structure
- node = vertex
- arc = edge
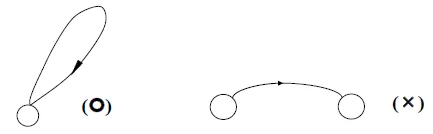
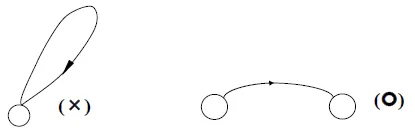
- active edge: (a) and (b)
- inactive edge: (c)
decorated grammar
- (a) “•” in the first
![]()
- • NP VP
- A hypothesis has been made, but has not been verified yet
- (b) “•” in the middle
![]()
- NP • VP
- A hypothesis has been partially confirmed
- (c) “•” in the last
- NP VP •
- A hypothesis has been wholly confirmed
- representation of edge
![]()
- initialization
![]()
- for each rule A → W, if A is a category that can span a chart (typically S), add <0, 0, A → •W>
![]()
- A implies •W from position 0 to 0
- for each rule A → W, if A is a category that can span a chart (typically S), add <0, 0, A → •W>
- Housekeeping
- prevent duplicate rules


Fundamental rule
- If the chart contains <i, j, A → W1 •B W2> and <j, k, B → W3 •>, then add edge <i, k, A → W1 B •W2> to the chart
![]()
- Notes
- New edge may be either active or inactive
- does not remove the active edge that has succeeded
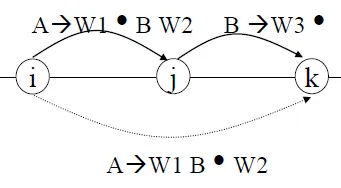
Bottom-up rule
- if adding edge <i, j, C → W1 •> to the chart, then for every rule that has the form B → C W2, add <i, i, B → • C W2>
![]()
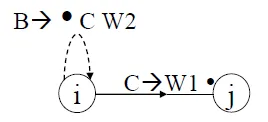
Top-down rule
- If adding edge <i, j, C → W1 •B W2> to the chart, then for each rule B → W, add < j, j, B →•W>
Full Syntactic Parsing
- necessary for deep semantic analysis of texts
- not practical for many applications (given typical resources)
- O(n^3) for straight parsing
- O(n^5) for probabilistic versions
- Too slow for real time applications (search engines)
- Two Alternatives
- Dependency parsing
- Change the underlying grammar formalism
- can get a lot done with just binary relations among the words
- 詳見Chap08 dependency grammar
- Partial parsing
- Approximate phrase-structure parsing with finite-state and statistical approaches
- Both of these approaches give up something (syntactic, structure) in return for more robust and efficient parsing
- Dependency parsing
Partial parsing
- For many applications you don’t really need full parse
- For example, if you’re interested in locating all the people, places and organizations
- base-NP chunking
- [NP The morning flight] from [NP Denvar] has arrived
- base-NP chunking
- Two approaches
- Rule-based (hierarchical) transduction(轉導)
- Restrict recursive rules (make the rules flat)
- like NP → NP VP
- Group the rules so that RHS of the rules can refer to non-terminals introduced in earlier transducers, but not later ones
- Combine the rules in a group in the same way we did with the rules for spelling changes
- Combine the groups into a cascade
- can be used to find the sequence of flat chunks you’re interested in
- or approximate hierarchical trees you get from full parsing with a CFG
- Typical Architecture 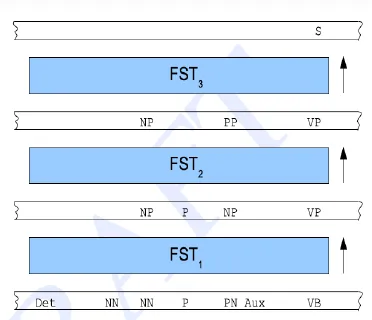
- Phase 1: Part of speech tags
- Phase 2: Base syntactic phrases
- Phase 3: Larger verb and noun groups
- Phase 4: Sentential level rules
- Restrict recursive rules (make the rules flat)
- Statistical sequence labeling
- HMMs
- MEMMs
- Rule-based (hierarchical) transduction(轉導)
Chap10 Statistical Parsing
Motivation
- N-gram models and HMM Tagging only allowed us to process sentences linearly
- Probabilistic Context Free Grammars(PCFG)
- alias: Stochastic context-free grammar(SCFG)
- simplest and most natural probabilistic model for tree structures
- closely related to those for HMMs
- 為每一個CFG的規則標示其發生的可能性
Idea
- reduce “right” parse to “most probable parse”
- Argmax P(Parse|Sentence)
A PCFG consists of
- set of terminals, {wk}
- set of nonterminals, {Ni}
- start symbol N1
- set of rules
- {Ni --> ξj}(ξj is a sequence of terminals and nonterminals)
- probabilities of rules
- total probability of imply Ni to other sequence ξj is 1
- ∀i Σj P(Ni → ξj) = 1
- Probability of sentence according to grammar G
- P($w_{1m}$) = sum of P($w_{1m}$, t) for every possible tree t
- Nj dominates the words wa … wb
- Nj → wa … wb
Assumptions of the Model
- Place Invariance
- probability of a subtree does not depend on its position in the string
- similar to time invariance in HMMs
- Ancestor Free
- probability of a subtree does not depend on nodes in the derivation outside the subtree(subtree的機率只和subtree內的node有關)
- can simplify probability calculation
![]()
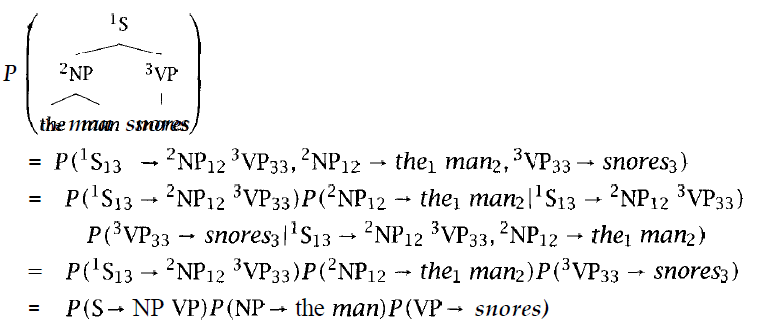
Questions of PCFGs(similar to three questions of HMM)
- Assign probabilities to parse trees
- What is the probability of a sentence $w_{1m}$ according to a grammar G
- P(w1m|G)
- What is the probability of a sentence $w_{1m}$ according to a grammar G
- Parsing with probabilities(Decoding)
- What is the most likely parse for a sentence
- argmax_t P(t|w1m,G)
- How to efficiently find the best (or N best) trees
- What is the most likely parse for a sentence
- Training the model (Learning)
- How to set rule probabilities(parameter of grammar model) that maximize the probability of a sentence
- argmax_G P(w1m|G)
- How to set rule probabilities(parameter of grammar model) that maximize the probability of a sentence
Simple Probability Model
- probability of a tree is the product of the probabilities of rules in derivation
- Rule Probabilities
- S → NP
- P(NP | S)
- Training the Model
- estimate probability from data
- P(α → β | α) = Count(α→β) / Count(α) = Count(α→β) / Σγ Count(α→γ)
- Parsing (Decoding)
- trees with highest probability in the model
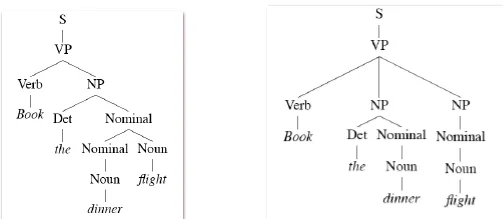
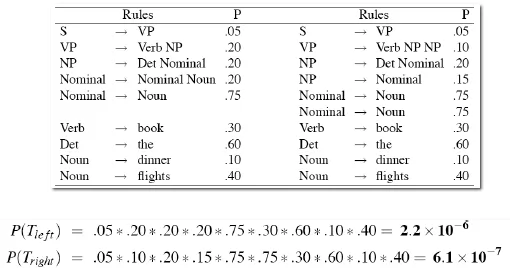
- Example: Book the dinner flight
![]()
![]()
- too slow!
Dynamic Programming again
- use CKY and Earley to parse
- Viterbi and HMMs to get the best parse
- Parameters of a PCFG in Chomsky Normal Form
- P(Nj→NrNs | G) , $n^3$ matrix of parameters
- P(Nj→wk | G), $nV$ parameters
- n is the number of nonterminals
- V is the number of terminals
- Σr,s P(Nj→NrNs) + ΣkP(Nj→wk) = 1
- 所有由Nj導出的rule,機率總和必為1
Probabilistic Regular Grammars (PRG)
- start state N1
- rules
- Ni → wjNk
- Ni → wj
- PRG is a HMM with [start state] and [finish(sink) state]
![]()
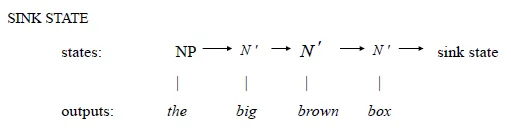
Inside and Outside probability 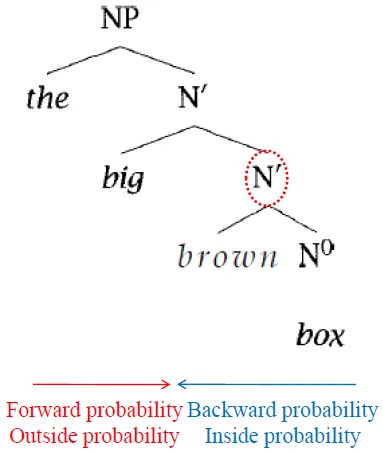
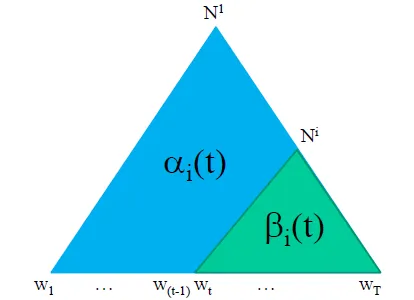
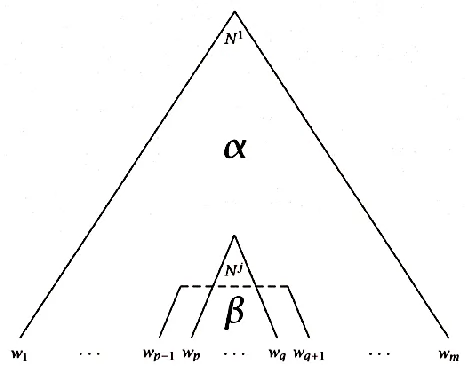
- Forward(Outside) probability
- $ α_i(t) = P(w_{1(t-1)}, X_t = i)$
- everything above a certain node(include the node)
- Backward(Inside) probability
- $ β_i(t, T) = P(w_{tT} | X_t = i)$
- everything below a certain node
- total probability of generating words $w_t \cdots w_T$, given the root nonterminal $N^i$ and a grammar G
Inside Algorithm (bottom-up)
- $P(w_{1m} | G) = P(N_1 → w_{1m} | G) = P(w_{1m} | N^1_{1m}, G) = B_1(1,m)$
- $B_1(1,m)$ is Inside probability
- P(w1~wm are below N1(start symbol))
- $B_1(1,m)$ is Inside probability
- base rule
- $ B_j(k, k) = P(w_k | N^j_{kk}, G) = P(N^j → w_k | G)$
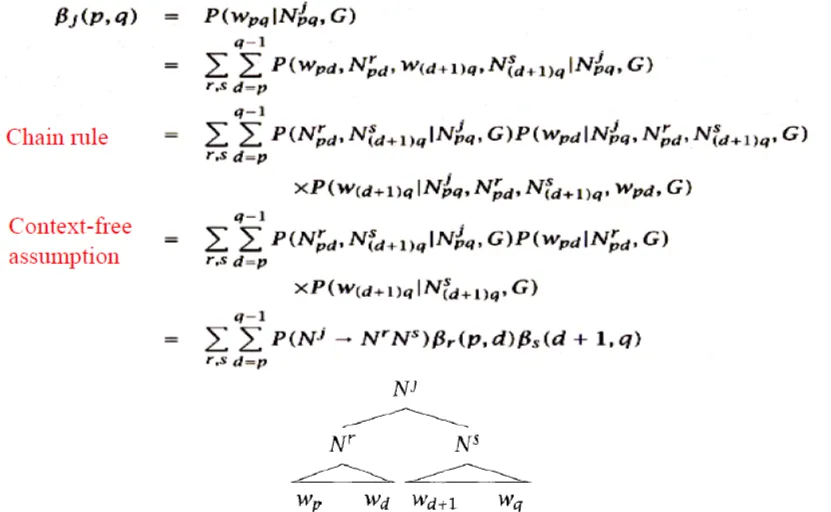
- $ B_j(p, q) = P(w_{pq} | N^j_{pq}, G) = $
![]()
- try every possible rules to split Nj, product of **rule probabilty and segments' inside probabilities **
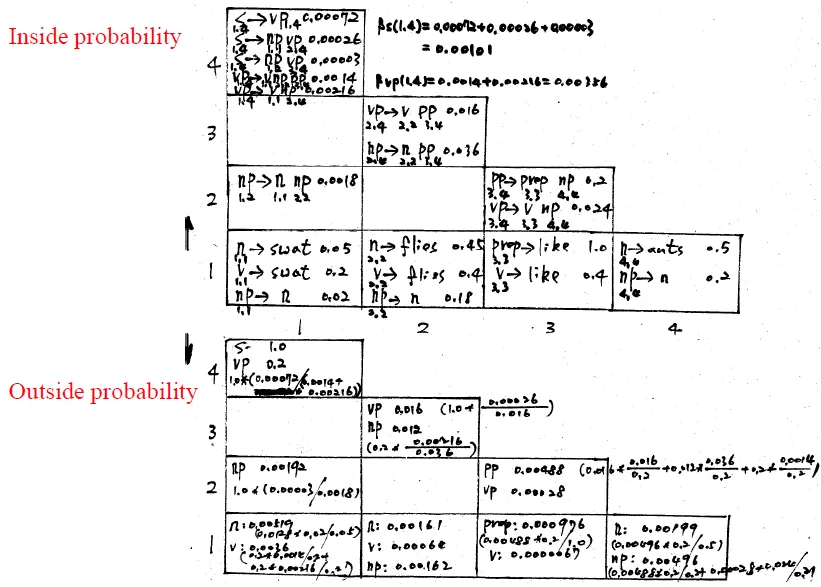
- use grid to solve again
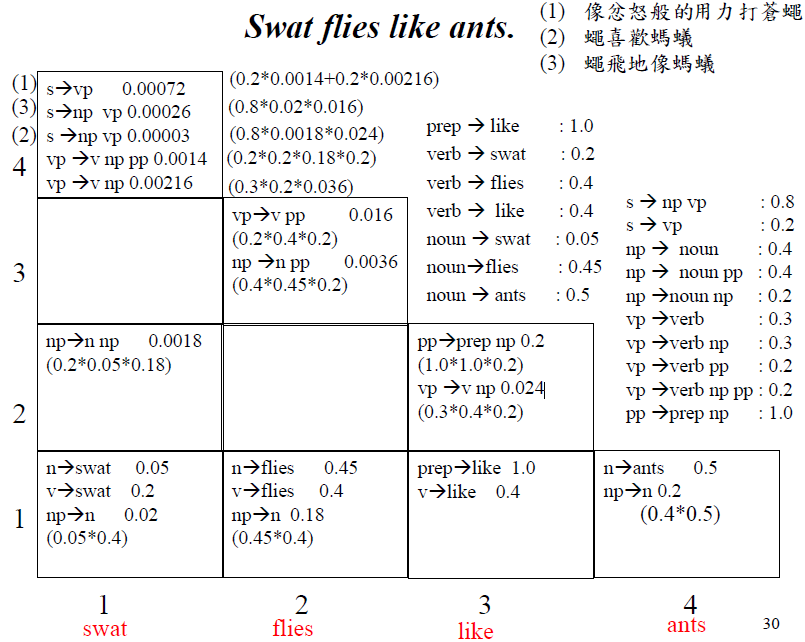
![]()
- X軸代表起始座標,Y軸代表長度
- (2,3) → flies like ants
- X軸代表起始座標,Y軸代表長度
Outside Algorithm (top-down)
- $ P(w_{1m} | G) = Σ_j α_j(k, k)P(N^j → w_k$
![]()
- outside probability of wk x (inside) probability of wk of every Nj
- basecase
- $ α_1(1, m) = 1, α_j(1,m) = $
- P(N1) = 1, P(Nj outside w1 to wm) = 0
- 自己的outside probability 等於
- 爸爸的outside probability 乘以 爸爸的inside probability 除以 自己的inside probability
- inside x outside 是固定值?
- 爸爸的inside probabiliity 除以 自己的inside probability 就是其兄弟的inside probability
- 使用此公式計算
![]()
- 爸爸的outside probability 乘以 爸爸的inside probability 除以 自己的inside probability
- $ α_j(p, q)β_j(p, q) = P(w_{1m}, N^j_{pq} | G) $
- 某個點的inside 乘 outside = 在某grammar中,出現此句子,且包含此點的機率
- 所有點的總和:在某grammar下,某parse tree(包含所有node)的機率
![]()
- Outside example: 這些數字理論上算起來會一樣…
![]()
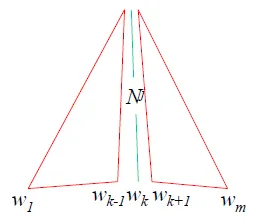

Finding the Most Likely Parse for a Sentence
- δi(p,q)= the highest inside probability parse of a subtree $N_{pq}^i$
- Initialization
- δi(p,p)= P(Ni → wp)
- Induction and Store backtrace
- δi(p,q)= $argmax(j,k,r)P(Ni→NjNk)δj(p,r)δk(r+1,q)$
- 找所有可能的切法
- Termination
- answer = δ1(1,m)
Training a PCFG
- find the optimal probabilities among grammar rules
- use EM Training Algorithm to seek the grammar that maximizes the likelihood of the training data
- Inside-Outside Algorithm
![]()
- 將產生句子的機率視為π,為Nj產生pq的機率
![]()
- Nj被使用的機率
![]()
- Nj被使用,且Nj→NrNs的機率
![]()
- Nj→NrNs這條rule被使用的機率=前兩式相除
![]()
- Nj→wk
![]()
- 僅分子差異
![]()
- 僅分子差異
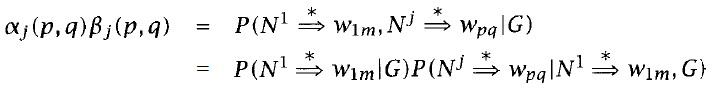
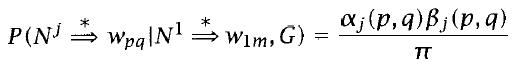
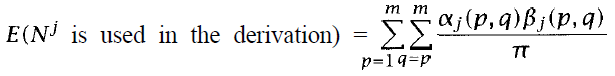
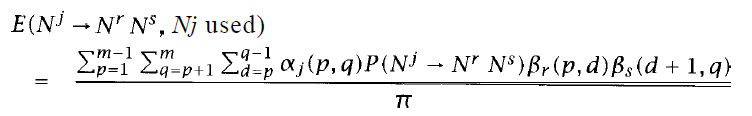
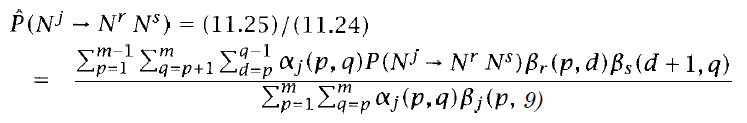
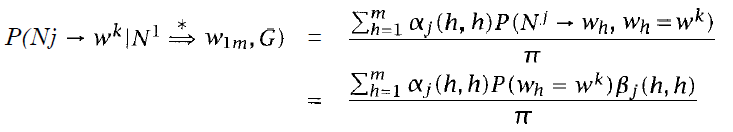
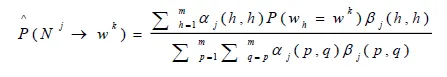
Problems with the Inside-Outside Algorithm
- Extremely Slow
- For each sentence, each iteration of training is $O(m^3n^3)$
- Local Maxima
- Satisfactory learning requires many more nonterminals than are theoretically needed to describe the language
- There is no guarantee that the learned nonterminals will be linguistically motivated
Chap11 Dependency Parsing
COLING-ACL 2006, Dependency Parsing, by Joachim Nivre and Sandra Kuebler
NAACL 2010, Recent Advances in Dependency Parsing, by Qin Iris. Wang and YueZhang
IJCNLP 2013, Dependency Parsing: Past, Present, and Future, by Zhenghua Li, Wenliang Chen, Min Zhang
Dependency Structure vs. Constituency Structure 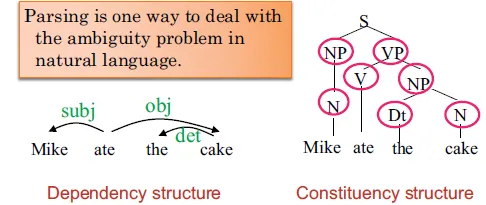
Parsing is one way to deal with the ambiguity problem in
natural language
dependency syntax is syntactic relations (dependencies)
Constraint: between word pairs 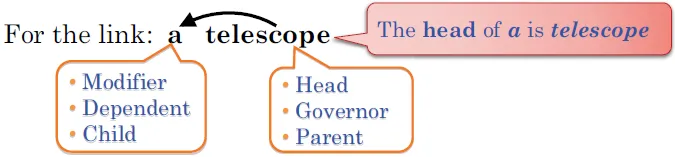
Projective: No crossing links(a word and its dependents form a contiguous substring of the sentence)
An arc (wi , r ,wj ) ∈ A is projective iff wi →∗ wk for all:
i < k < j when i < j
j < k < i when j < i
射出去的那一方也可以射到兩個字中間的任何一字
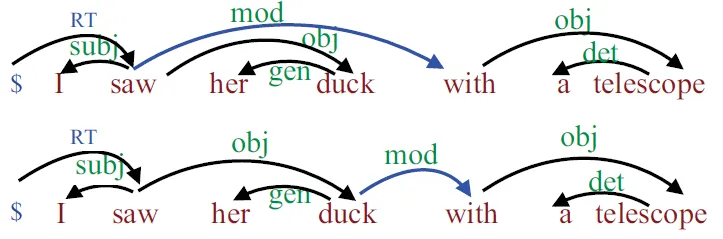
Non-projective Dependency Trees
- Long-distance dependencies
- With crossing links
- Not so frequent in English
- All the dependency trees from Penn Treebank are projective
- Common in other languages with free word order
- Prague(23%) and Czech, German and Dutch
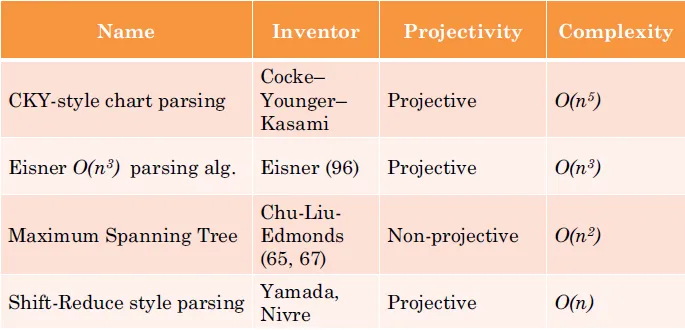
Data Driven Dependency Parsing
- Data-driven parsing
- No grammar / rules needed
- Parsing decisions are made based on learned models
- deal with ambiguities well
![]()
- Three approaches
- Graph-based models
- Transition-based models(good in practice)
- Define a transition system for mapping a sentence to its dependency tree
- Predefine some transition actions
- Learning: predicting the next state transition, by transition history
- Parsing: construct the optimal transition sequence
- Greedy search / beam search
- Features are defined over a richer parsing history
- Hybrid models
Comparison
- Graph-based models
- Find the optimal tree from all the possible ones
- Global, exhaustive
- Transition-based models
- Predefine some actions (shift and reduce)
- use stack to hold partially built parses
- Find the optimal action sequence
- Local, Greedy or beam search
- The two models produce different types of errors
Hybrid Models
- Three integration methods
- Ensemble approach: parsing time integration (Sagae & Lavie 2006)
- Feature-based integration (Nivre & Mcdonald 2008)
- Single model combination (Zhang & Clark 2008)
- Gain benefits from both models
Graph-based dependency parsing models
- Search for a tree with the highest score
- Define search space
- Exhaustive search
- Features are defined over a limited parsing history
- The score is linear combination of features
- What features we can use? (later)
- What learning approaches can lead us to find the best tree with the highest score (later)
- Applicable to both probabilistic and nonprobabilistic models
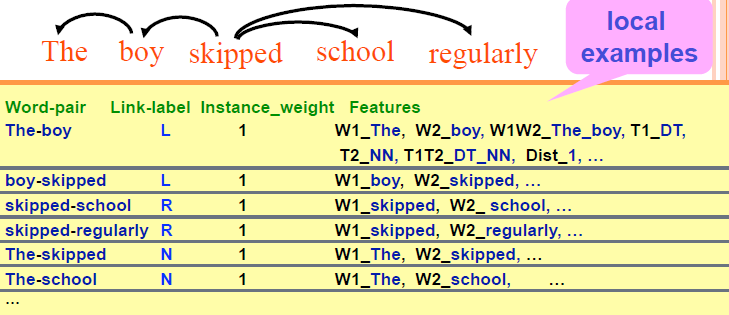
Features
- dynamic features
- Take into account the link labels of the surrounding word-pairs when predicting the label of current pair
- Commonly used in sequential labeling
- A word’s children are generated first(先生child, 再找parent), before it modifies another word
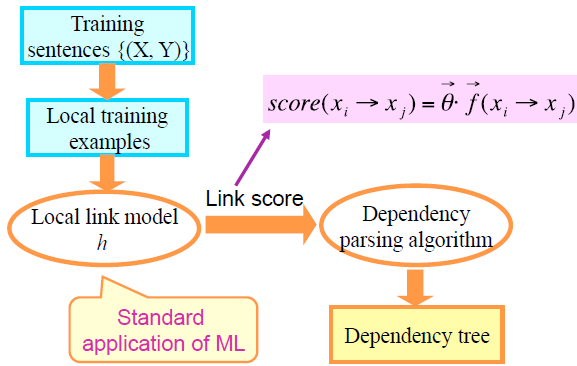
Learning Approaches
- Local learning approaches
- Learn a local link classifier given of features defined on training data
- example
![]()
- 3-class classification: No link, left link or right link
- Efficient O(n) local training
- local training and parsing
![]()
- Learn the weights of features
- Maximum entropy models (Ratnaparkhi 99, Charniak 00)
- Support vector machines (Yamada & Matsumoto 03)
- Use a richer feature set!
- Global learning approaches
- Unsupervised/Semi-supervised learning approaches
- Use both annotated training data and un-annotated raw text
Transition-based model
- Stack holds partially built parses
- Queue holds unprocessed words
- Actions
- use input words to build output parse
parsing processes
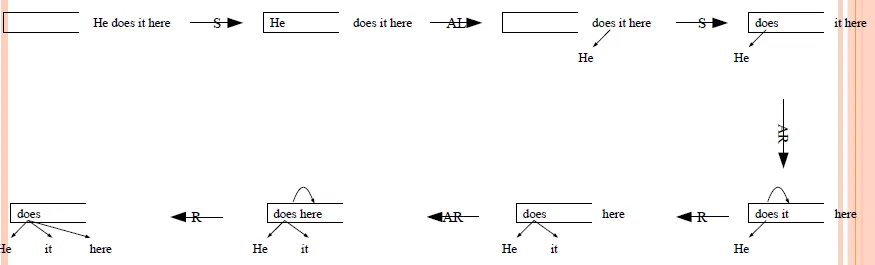
Arc-eager parser
- 4 tranition actions
- SHIFT: push stack
- REDUCE: pop stack
- ARC-LEFT: pop stack and add link
- ARC-RIGHT: push stack and add link
![]()
- Time complexity: linear
- every word will be pushed once and popped once(except root)
- parse
- by actions: arcleft → arclect subject, noun, ...
Arc-standard parser
- 3 actions
- SHIFT: push
- LEFT: pop leftmost stack element and add
- RIGHT: pop rightmost stack element and add
- Also linear time
Non-projectivity
- neither of parser can solve it
- online reorder
- add extra action: swap
- not linear: $N^2$, but expect to belinear
- online reorder
Decoding algorithms
search action sequence to build the parse
scoring action given context
Candidate item <S, G, Q>
- greedy local search
- initialize: Q = input
- goal: S=[root], G=tree, Q=[]
- problem: one error leads to incorrect parse
- Beam search: keep N highest partial states
- use total score of all actions to rank a parse
- Beam search: keep N highest partial states
Score Models
- linear model
- SVM
Chap12 Semantic Representation and Computational Semantics
Semantic aren’t primarily descriptions of inputs
Semantic Processing
- reason about the truth
- answer questions based on content
- Touchstone application is often question answering
- inference to determine the truth that isn't actually know
Method
- principled, theoretically motivated approach
- Computational/Compositional Semantics
- limited, practical approaches that have some hope of being useful
- Information extraction
Information Extraction
Information Extraction = segmentation + classification + association + clustering 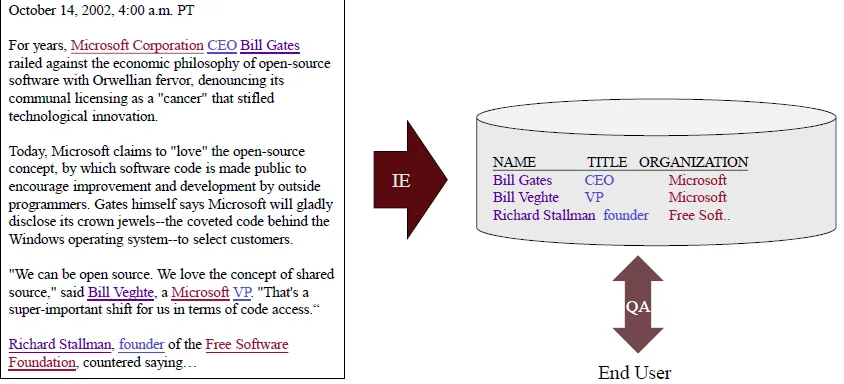
- superficial analysis
- pulls out only the entities, relations and roles related to consuming application
- Similar to chunking
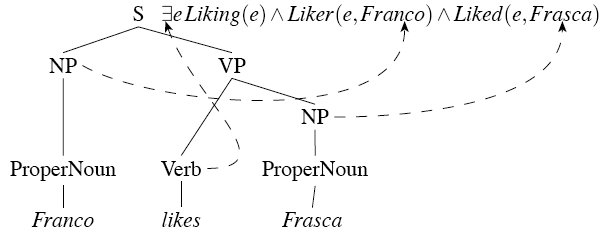
Compositional Semantics
- Use First-Order Logic(FOL) representation that accounts for all the entities, roles and relations present in a sentence
- Similar to our approach to full parsing
- Compositional: The meaning of a whole is derived from the meanings of the parts(syntatic)
![]()
- Syntax-Driven Semantic Analysis
- The composition of meaning representations is guided by the syntactic components and relations provided by the grammars
FOL
- allow to answer yes/no questions
- allow variable
- allow inference
Events, actions and relationships can be captured with representations that consist of predicates with arguments
- Predicates
- Primarily Verbs, VPs, Sentences
- Verbs introduce/refer to events and processes
- Arguments
- Primarily Nouns, Nominals, NPs, PPs
- Nouns introduce the things that play roles in those events
- Example: Mary gave a list to John
- Giving(Mary, John, List)
- Gave: Predicate
- Mary, John, List: Argument
- better representation
![]()
- Lambda Forms
- Allow variables to be bound
- λxP(x)(Sally) = P(Sally)
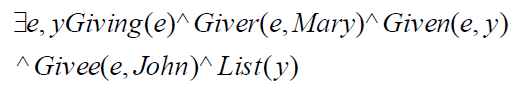
Ambiguation
- mismatch between syntax and semantics
- displaced arguments
- complex NPs with quantifiers
- A menu
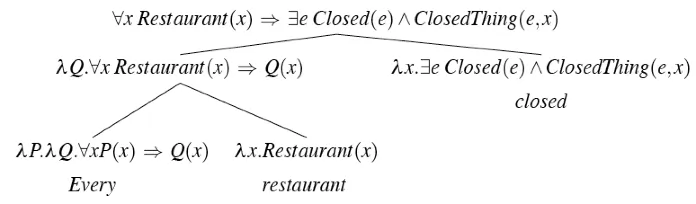
- Every restaurant
![]()
- Not every waiter
- Most restaurants
![]()
- still preserving strict compositionality
- Two (syntax) rules to revise
- The S rule
- S → NP VP, NP.Sem(VP.Sem)
- NP and VP swapped, because S is NP
- Simple NP's like proper nouns
- λx.Franco(x)
- The S rule
- Store and Retrieve
![]()
- Retrieving the quantifiers one at a time and placing them in front
- The order determines the meaning
![]()
- retrieve
![]()
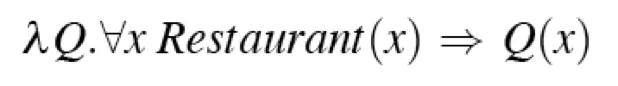

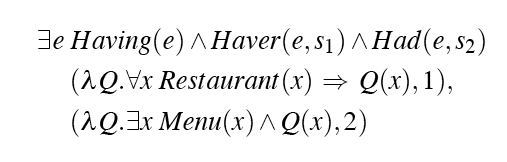
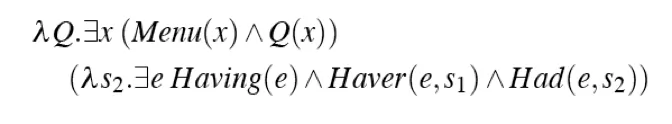
Set-Based Models
- domain: the set of elements
- entity: elements of domain
- Properties of the elements: sets of elements from the domain
- Relations: sets of tuples of elements from the domain
- FOL
- FOL Terms → elements of the domain
- Med -> “f”
- FOL atomic formula → sets, or sets of tuples
- Noisy(Med) is true if “f is in the set of elements that corresponds to the noisy relation
- Near(Med, Rio) is true if “the tuple <f,g> is in the set of tuples that corresponds to “Near” in the interpretation
- FOL Terms → elements of the domain
- Example: Everyone likes a noisy restaurant
![]()
- There is a particular restaurant out there; it’s a noisy place; everybody likes it 有一家吵雜的餐廳大家都喜歡
- Everybody has at least one noisy restaurant that they like 大家都喜歡一家吵雜的餐廳
- Everybody likes noisy restaurants (i.e., there is no noisy restaurant out there that is disliked by anyone) 大家都喜歡吵雜的餐廳
- Using predicates to create categories of concepts
- people and restaurants
- basis for OWL (Web Ontology Language)網絡本體語言
- before
![]()
- after
![]()

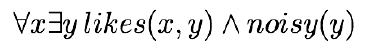

Chap13 Lexical Semantics
we didn’t do word meaning in compositional semantics
WordNet
- meaning and relationship about words
- hypernym(上位詞)
- breakfast → meal
- hierarchies
![]()
- hypernym(上位詞)

In our semantics examples, we used various FOL predicates to capture various aspects of events, including the notion of roles
Havers, takers, givers, servers, etc.
Thematic roles(語義關係) 
- semantic generalizations over the specific roles that occur with specific verbs
- provide a shallow level of semantic analysis
- tied to syntactic analysis
- i.e. Takers, givers, eaters, makers, doers, killers
- They’re all the agents of the actions
- AGENTS are often subjects
- In a VP->V NP rule, the NP is often a THEME
2 major English resources using thematic data
- PropBank
- Layered on the Penn TreeBank
- Small number (25ish) labels
- FrameNet
- Based on frame semantics
- Large number of frame-specific labels
Example
- [McAdams and crew] covered [the floors] with [checked linoleum].格子花紋油毯
- Arg0 (agent: the causer of the smearing)
- Arg1 (theme: “thing covered”)
- Arg2 (covering: “stuff being smeared”)
- including agent and theme, remaining args are verb specific
Logical Statements
- Example: EAT -- Eating(e) ^Agent(e,x)^ Theme(e,y)^Food(y)
- (adding in all the right quantifiers and lambdas)
- Use WordNet to encode the selection restrictions
- Unfortunately, language is creative
- … ate glass on an empty stomach accompanied only by water and tea
- you can’t eat gold for lunch if you’re hungry
can we discover a verb’s restrictions by using a corpus and WordNet?
- Parse sentences and find heads
- Label the thematic roles
- Collect statistics on the co-occurrence of particular headwords with particular thematic roles
- Use the WordNet hypernym structure to find the most meaningful level to use as a restriction
WSD
Word sense disambiguation
- select right sense for a word
- Semantic selection restrictions can be used to disambiguate
- Ambiguous arguments to unambiguous predicates
- Ambiguous predicates with unambiguous arguments
- Ambiguous arguments
- Prepare a dish(菜餚)
- Wash a dish(盤子)
- Ambiguous predicates
- Serve (任職/服務) Denver
- Serve (供應) breakfast
Methodology
- Supervised Disambiguation
- based on a labeled training set
- Dictionary-Based Disambiguation
- based on lexical resource like dictionaries
- Unsupervised Disambiguation
- label training data is expensive
- based on unlabeled corpora
- Upper(human) and Lower(simple model) Bounds
- Pseudoword
- Generate artificial evaluation data for comparison and improvement of text processing algorithms
Supervised ML Approaches
- What’s a tag?
- In WordNet, “bass” in a text has 8 possible tags or labels (bass1 through bass8)
- require very simple representation for training data
- Vectors of sets of feature/value pairs
- need to extract training data by characterization of text surrounding the target
- If you decide to use features that require more analysis (say parse trees) then the ML part may be doing less work (relatively) if these features are truly informative
- Classification
- Naïve Bayes (the right thing to try first)
- Decision lists
- Decision trees
- MaxEnt
- Support vector machines
- Nearest neighbor methods…
- choice of technique depends on features that have been used
- Bootstrapping
- Use when don’t have enough data to train a system…
- 集中有放回的均勻抽樣
Naive Bayes
- Argmax P(sense|feature vector)
![]()
- find maximum probabilty of words given possible sk
![]()
![]()
- assumption
- bag of words model
- structure and order of words is ignored
- each pair of words in the bag is independent
- bag of words model
- 73% correct
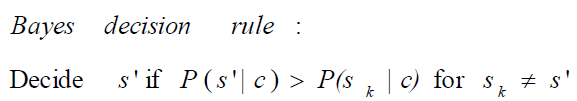
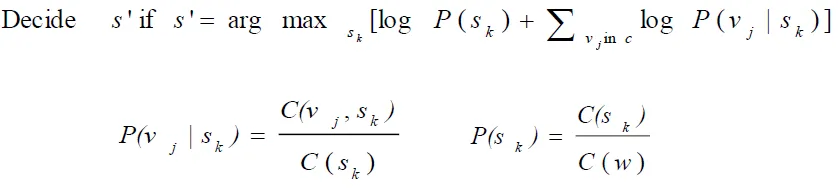

Dictionary-Based Disambiguation
- Disambiguation based on sense definitions
- Thesaurus-Based Disambiguation
- Disambiguation based on translations in a second-language corpus
sense definition
- find keywords in definition of a word
- cone
- ... pollen-bearing scales or bracts in trees
- shape for holding ice cream
- 50%~70% accuracies
- Alternatives
- Several iterations to determine correct sense
- Combine the dictionary-based and thesaurus-based disambiguation
- cone
Thesaurus-Based(索引典) Disambiguation
- Category can determine which word senses are used
- Each word is assigned one or more subject codes which correspond to its different meanings
- select the most often subject code
- 考慮w的context,有多少words的senses與w相同
- Walker’s Algorithm
- 50% accuracy for "interest, point, power, state, and terms"
- Problems
- general topic categorization, e.g., mouse in computer
- coverage, e.g., Navratilova
- Yarowsky's Algorithm
![]()
![]()
![]()
-
- categorize sentences
-
- categorize words
-
- disambiguate by decision rule for Naïve Bayes
- result
![]()
-


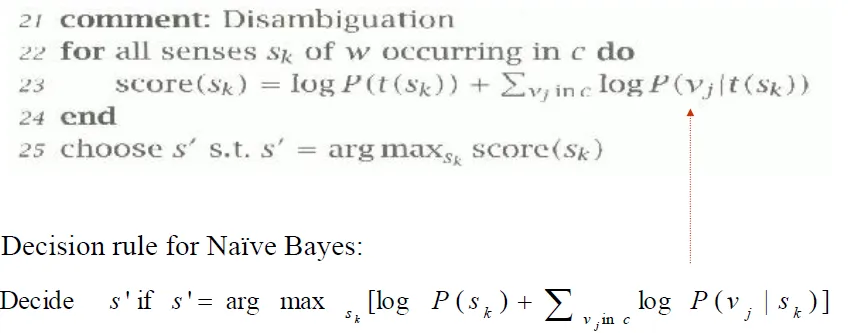

Disambiguation based on translations in a second-language corpus
- the word “interest” has two translations in German
- “Beteiligung” (legal share--50% a interest in the company)
- “Interesse” (attention, concern--her interest in Mathematics)
- Example: … showed interest …
- Look up English-German dictionary, show → zeigen
- Compute R(Interesse, zeigen) and R(Beteiligung, zeigen)
- R(Interesse, zeigen) > R(Beteiligung, zeigen)
Unsupervised Disambiguation
P(vj|sk) are estimated using the EM algorithm
- Random initialization of P(vj|sk)(word)
- For each context ci of w, compute P(ci|sk)(sentence)
- Use P(ci|sk) as training data
- Reestimate P(vj|sk)(word)
Surface Representations(features)
- Collocational
- words that appear in specific positions to the right and left of the target word
- limited to the words themselves as well as part of speech
- Example: guitar and bassplayer stand
- [guitar, NN, and, CJC, player, NN, stand, VVB]
- In other words, a vector consisting of [position n word, position n part-of-speech…]
- Co-occurrence
- words that occur regardless of position
- Typically limited to frequency counts
- Assume we’ve settled on a possible vocabulary of 12 words that includes guitarand playerbut not andand stand
- Example: guitar and bassplayer stand
- Assume a 12-word sentence includes guitar and player but not "and" and stand
- [0,0,0,1,0,0,0,0,0,1,0,0]
Applications
- tagging
- translation
- information retrieval
different label
- Generic thematic roles (aka case roles)
- Agent, instrument, source, goal, etc.
- Propbank labels
- Common set of labels ARG0-ARG4, ARGM
- specific to verb semantics
- FrameNet frame elements
- Conceptual and frame-specific
- Example: [Ochocinco] bought [Burke] [a diamond ring]
- generic: Agent, Goal, Theme
- propbank: ARG0, ARG2, ARG1
- framenet: Customer, Recipe, Goods
Semantic Role Labeling
- automatically identify and label thematic roles
- For each verb in a sentence
- For each constituent
- Decide if it is an argument to that verb
- if it is an argument, determine what kind
- For each constituent
- For each verb in a sentence
- feature
- from parse and lexical item
- "path"
Lexical Acquisition
- Verb Subcategorization
- the syntactic means by which verbs express their arguments
- Attachment Ambiguity
- The children ate the cake with their hands
- The children ate the cake with blue icing
- SelectionalPreferences
- The semantic categorization of a verb’s arguments
- Semantic Similarity (refer to IR course)
- Semantic similarity between words
Verb Subcategorization
a particular set of syntactic categories that a verb can appear with is called a subcategorization frame 
Brent’s subcategorization frame learner
- Cues: Define a regular pattern of words and syntactic categories
- ε: error rate of assigning frame f to verb v based on cue cj
- Hypothesis Testing: Define null hypothesis H0: “the frame is not appropriate for the verb”
- Reject this hypothesis if the cue cj indicates with high probability that our H0 is wrong
Example
Cues
-
regular pattern for subcategorization frame “NP NP”
- (OBJ | SUBJ_OBJ | CAP) (PUNC |CC)
Null hypothesis testing
- (OBJ | SUBJ_OBJ | CAP) (PUNC |CC)
-
Verb vi occurs a total of n times in the corpus and there are m < n occurrences with a cue for frame fj
-
Reject the null hypothesis H0 that vi does not accept fj with the following probability of error
![]()
-
Brent’s system does well at precision, but not well at recall
-
Manning’s system
- solve this problem by using a tagger and running the cue detection on the output of the tagger
- learn a lot of subcategorization frames, even those it is low-reliability
- still low performance
- improve : use prior knowledge
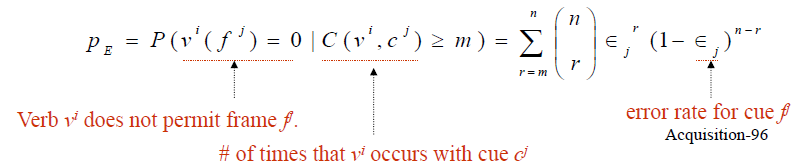
PCFG prefers to parse common construction
- P(A|prep, verb, np1, np2, w) ~= P(A|prep, verb, np1, np2)
- Do not count the word outside of frame
- w: words outside of “verb np1(prep np2)”
- A: random variable representing attachment decision
- V(A): verb or np1
- Counter example
- Fred saw a movie with Arnold Schwarzenegger
- P(A|prep, verb, np1, np2, noun1, noun2) ~= P(A|prep, verb, noun1, noun2)
- noun1 = head of np1, noun2 = head of np2
- total parameters: $10^{13}$ = #(prep) x #(verb) x #(noun) x #(noun)
- P(A= noun | prep, verb, noun1) vs. P(A= verb | prep, verb, noun1)
- compare probability to be verb and probability to be noun
Technique: Alternative to reduce parameters
- Condition probabilities on fewer things
- Condition probabilities on more general things
The model asks the following questions
- VAp: Is there a PP headed by p and following the verb v which attaches to v(VAp=1) or not (VAp=0)?
- NAp: Is there a PP headed by p and following the noun n which attaches to n (NAp=1) or not (NAp=0)?
- (1) Determine the attachment of a PP that is immediately following an object noun, i.e. compute the probability of NAp=1
- In order for the first PP headed by the preposition p to attach to the verb, both VAp=1 and NAp=0
- calculate likelihood ratio between V and N
![]()
- maximum estimation
- P(VA = 1 | v) = C(v, p) / C(v)
- P(NA = 1 | n) = C(n, p) / C(n)
- calculate likelihood ratio between V and N
- Estimation of PP attachment counts
- Sure Noun Attach
- If a noun is followed by a PP but no preceding verb, increment C(prep attached to noun)
- Sure Verb Attach
- if a passive verb is followed by a PP other than a “by” phrase, increment C(prep attached to verb)
- if a PP follows both a noun phrase and a verb but the noun phrase is a pronoun, increment C(prep attached to verb)
- Ambiguous Attach
- if a PP follows both a noun and a verb, see if the probabilities based on the attachment decided by previous way
- otherwise increment both attachment counters by 0.5
![]()
- Sparse data is a major cause of the difference between the human and program performance(attachment indeterminacy不確定性)
- Sure Noun Attach


Using Semantic Information
- condition on semantic tags of verb & noun
- Sue bought a plant with Jane(human)
- Sue bought a plant with yellow leaves(object)
Assumption
The noun phrase serves as the subject of the relative clause
- collect “ subject-verb” and “verb-object” pairs.(training part)
- compute t-score (testing part)
- t-score > 0.10 (significant)
P (relative clause attaches to x | main verb of clause =v) > P (relative clause attaches to y | main verb of clause=v)
↔ P (x= subject/object | v) > P (y= subject/ object|v)
Selectional Preferences
- Most verbs prefer particular type of arguments
- eat → object (food item)
- think → subject (people)
- bark → subject (dog)
- Aspects of meaning of a word can be inferred
- Susan had never eaten a fresh durian before (food item)
- Selectional preferences can be used to rank different parses of a sentence
- Selectional preference strength
- how strongly the verb constrains its direct object
![]()
- KL divergence between the prior distribution of direct objects of general verb and the distribution of direct objects of specific verb
- 2 assumptions
- only the head noun of the object is considered
- rather than dealing with individual nouns, we look at classes of nouns
- Selectional association
- Selectional Association between a verb and a class is this class's contribution to S(v) / the overall preference strength S(v)
![]()
- There is also a rule for assigning association strengths to nouns instead of noun classes
- If noun belongs to several classes, then its choose the highest association strength among all classes
- estimating the probability that a direct object in noun class c occurs given a verb v
- A(interrupt, chair) = max(A(interrupt, people), A(interrupt, furniture)) = A(interrupt, people)
- Selectional Association between a verb and a class is this class's contribution to S(v) / the overall preference strength S(v)
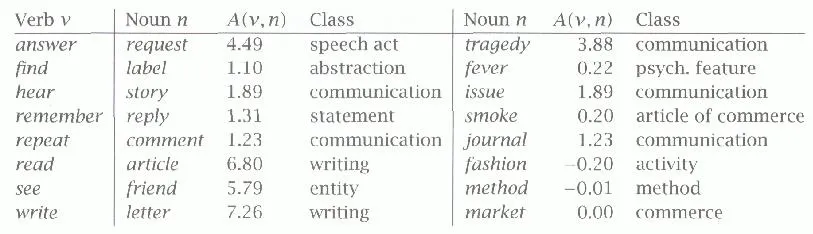
- Example
![]()
- eat prefers fooditem
- A(eat, food)=1.08 → very specific
- seehas a uniform distribution
- A(see, people)=A(see, furniture)=A(see, food)=A(see, action)=0 → no selectional preference
- find disprefers action item
- A(find, action)=-0.13 → less specific
- eat prefers fooditem

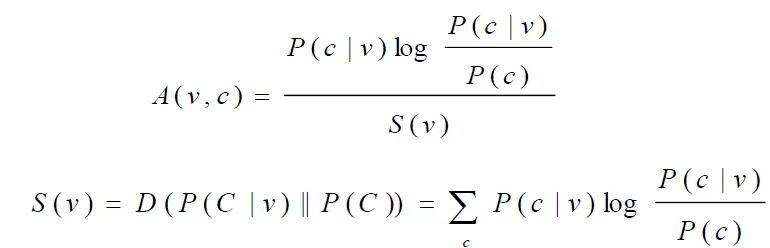
Semantic Similarity
- assessing semantic similarity between a new word and other already known words
- Vector Space vs Probabilistic
- Vector Space
- Words can be expressed in different spaces: document space, word spaceand modifier space
- Similarity measures for binary vectors: matching coefficient, Dice coefficient, Jaccard(or Tanimoto) coefficient, Overlap coefficientand cosine
- Similarity measures for the real-valued vector space: cosine, Euclidean Distance, normalized correlation coefficient
- cosine assumes a Euclidean space which is not well-motivated when dealing with word counts
![]()
- Probabilistic Measures
- viewing word counts by representing them as probability distributions
- compare two probability distributions using
- KL Divergence
- Information Radius(Irad)
- L1Norm

Chap14 Computational Discourse
| Level | Well-formedness constraints | Types of ambiguity |
|---|---|---|
| Lexical | Rules of inflection and derivation | |
| structural, morpheme boundaries, morpheme identity | ||
| Syntactic | Grammar rules | structural, POS |
| Semantic | Selection restrictions | word sense, quantifier scope |
| Pragmatic | conversation principles | pragmatic function |
Computational Discourse
- Discourse(語篇)
- A group of sentences with the same coherence relation
- Coherence relation
- the 2nd sentence offers the reader an explaination or cause for the 1st sentence
- Entity-based Coherence
- relationships with the entities, introducing them and following them in a focused way
- Discourse Segmentation
- Divide a document into a linear sequence of multiparagraph passages
- Academic article
- Abstract
- Introduction
- Methodology
- Results
- Conclusion
![Inverted Pyramid]()
- Applications
- News
- Summarize different segments of a document
- Extract information from inside a single discourse segment

TextTiling (Hearst,1997)
- Tokenization
- Each space-delimited word in the input is converted to lower-case
- Words in a stop list of function words are thrown out
- The remaining words are morphologically stemmed
- The stemmed words are grouped into pseudo-sentencesof length w = 20
- Lexical score determination
- compute a lexical cohesion(結合) score between pseudo-sentences
- score: average similarity of words in the pseudo-sentences before gap to pseudo-sentences after the gap(??)
- compute a lexical cohesion(結合) score between pseudo-sentences
- Boundary identification
- Compute a depth score for each gap
- Boundaries are assigned at any valley which is deeper than a cutoff
Coherence Relations
- Result
- The Tin Woodman was caught in the rain. His joints rusted
- Explanation
- John hid Bill’s car keys. He was drunk
- Parallel
- The Scarecrow wanted some brains
- The Tin Woodman wanted a heart
- Elaboration(詳細論述)
- Dorothy was from Kansas
- She lived in the midst of the great Kansas prairies
- Occasion(起因)
- Dorothy picked up the oil-can
- She oiled the Tin Woodman’s joints
Coherence Relation Assignment
- Discourse parsing
- Open problems
Cue-Phrase-Based Algorithm
-
Using cue phrases
- Segment the text into discourse segments
- Classify the relationship between each consecutive discourse
-
Cue phrase
- connectives, which are often conjunctions or adverbs
- because, although, but, for example, yet, with, and
- connectives, which are often conjunctions or adverbs
-
discourse uses vs. sentential uses
- With its distant orbit, Mars exhibits frigid weather conditions. (因為長距離的運行軌道,火星天氣酷寒)
- We can see Mars with an ordinary telescope
-
![]()
-
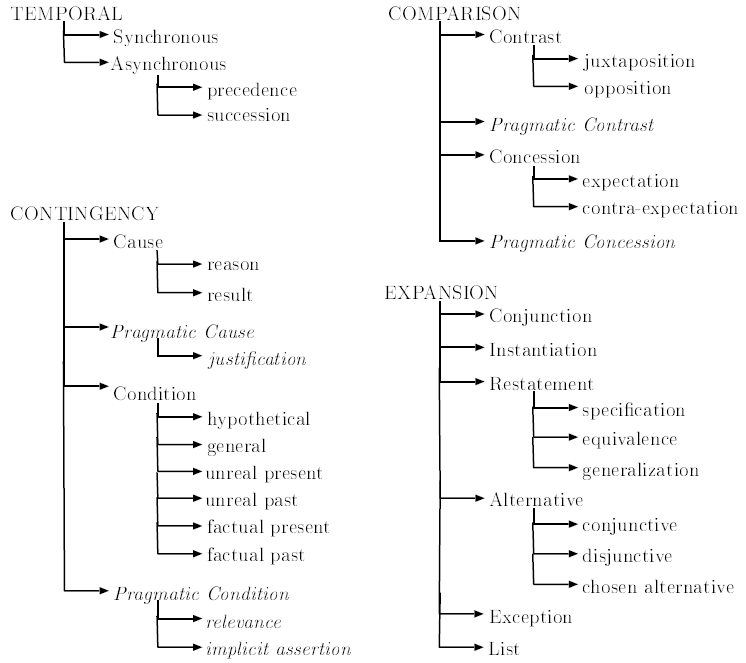
Temporal Relation
- ordered in time (Asynchronous)
- before, after ...
- overlapped (Synchronous)
- at the same time
- ordered in time (Asynchronous)
-
Contingency Relation
- 因果關係,附帶條件
-
Comparison Relation
- difference between two arguments
-
Expansion Relation
- expands the information for one argument in the other one or continues the narrative flow
-
Implicit Relation
- Discourse marker is absent
- 颱風來襲,學校停止上課
-
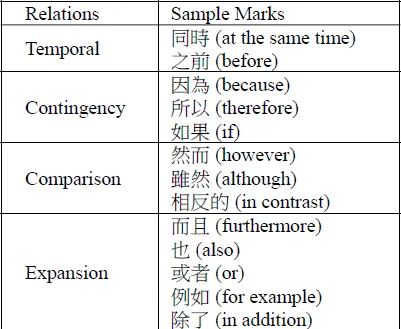
Chinese Relation Words
![]()
- Ambiguous Discourse Markers
- 而:而且, 然而, 因而
- Ambiguous Discourse Markers
Reference Resolution
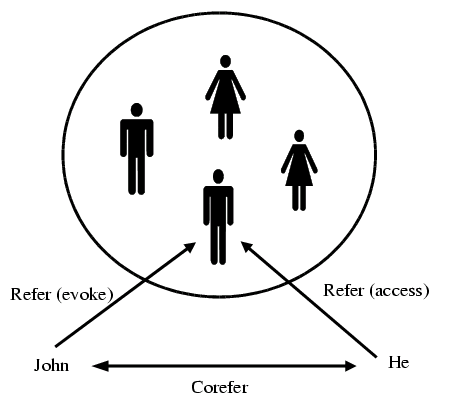
- Evoke
- When a referent is first mentioned in a discourse, we say that a representation for it is evoked into the model
- Access
- Upon subsequent mention, this representation is accessed from the model
Five Types of Referring Expressions
- Indefinite Noun Phrases(不定名詞)
- marked with the determiner a, some, this ...
- Create a new internal symbol and add to the current world model
- Mayumi has bought a new automobile
- automobile(g123)
- new(g123)
- owns(mayumi, g123)
- non-specific sense to describe an object
- Mayumi wantsto buy a new XJE
- whole classes of objects
- A new automobiletypically requires repair twice in the first 12 months
- collect one or more properties
- The Macho GTE XL is a new automobile
- Question and commands
- Is her automobile in a parking placenear the exit?
- Put her automobile into a parking placenear the exit!
- Definite Noun Phrases(定名詞)
- simple referential and generic uses(the same as indefinite)
- indicate an individual by description that they satisfy
- The manufacturer of this automobile should be indicted
- Pronouns(代名詞)
- reference backs to entities that have been introduced by previous nounphrases in a discourse
- non-referential noun phrase
- non-exist object
- logical variable
- No male driveradmits that heis incompetent
- something that is available from the context of utterance, but has not been explicitly mentioned before
- Here they come, late again!
- Can't easily know who are "they"
- Anaphora
- Number Agreements
- John has a Ford Falcon. It is red
- John has three Ford Falcons. They are red
- Person Agreement(人稱)
- Gender Agreement
- Selection Restrictions
- verb and its arguments
- Number Agreements
- Demonstratives (指示詞)
- this, that
- Names
- Full name > long definite description > short definite description > last name> first name > distal demonstrative > proximate demonstrative > NP > stressed pronoun > unstressed pronoun
Information Status
- Referential forms used to provide new or old information
- givenness hierarchy
![]()
- Definite-indefinite is a clue to given-new status
- The sales managere(given) employed a foreign distributor(new)
- If there are ambiguous noun phrases in a sentence, then it extracts the presuppositions to provide extra constraints
- When some new information is added to knowledge base, check if it is consistent with what we already know

Active model of understanding
- Given a text, build up predictions or expectations about new information and actively compare these with successive input to resolve ambiguities
- Construct a proof of the information provided in a sentence from the existing world knowledge and plausible inference rules illustrated
- the inference are not sensitive to the order
- if the proposition that the disc is heavy is inferred, then it is not changed after the discourse has finished
- Solution: describe the propositions in temporal order
- Script: encapsulate a sequence of actions that belong together into a script
1 | automobile_buying: |
參考資料
- HHChen 課堂講義